
不是一定要,而是空一个之后代码更简洁统一性更强,不用加额外的条件判断。
牺牲一个元素大小的内存换取更统一简单的代码是值得的。如果你不这么认为也可以用自己的方法,并不是强制要求。
就是为了能区分队列是满的还是空的。
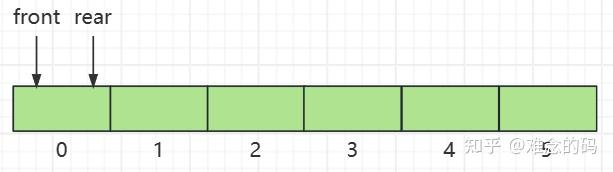
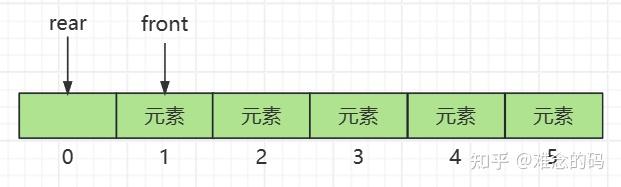
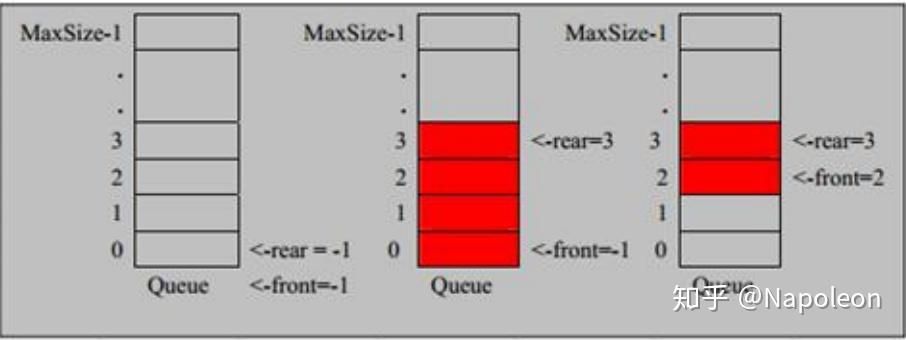
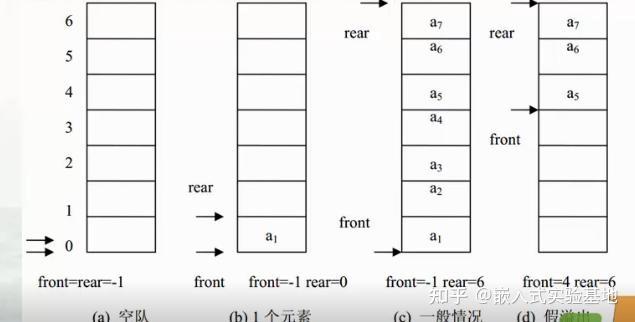
对于一个循环队列,有 front 和 rear 两个指针。当我们用数组表示,在初始状态,front 和 rear 指向同一个位置在位置 0,此时队列是空的。
也就是,如果 front == rear,则队列为空。
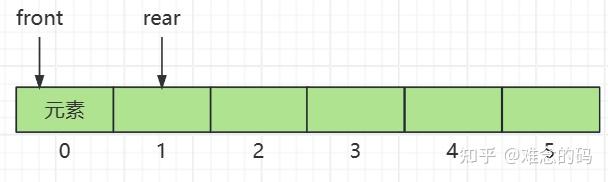
当我们加入一个元素后,rear 指针向后移动一位, front 指针不变。
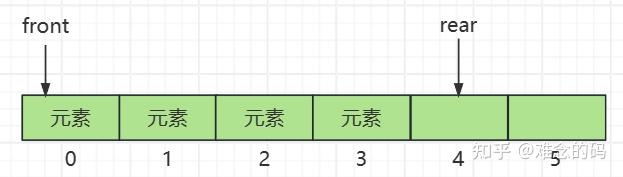
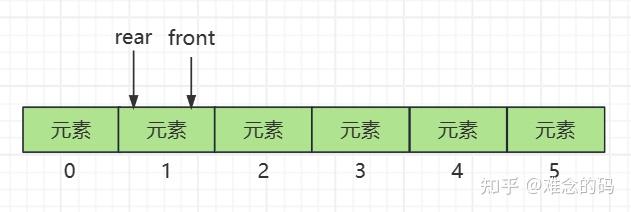
然后我们再加入三个元素,此时队列的情况如图所示。
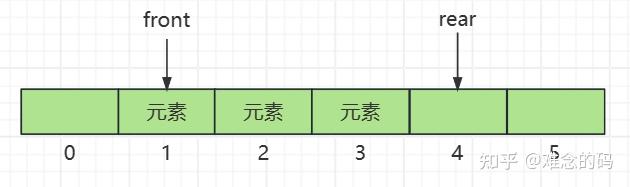
顺便演示一下,删除一个元素吧,从头部删除,此时 front 指针向后移动一位。
再加入两个元素到队列中,看看此时的情况。
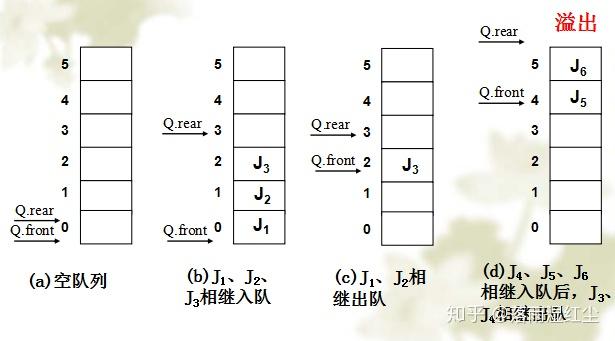
那么此时就已经满了,我们有 (rear + 1)%size == front 作为循环队列满了的条件。这个条件与循环队列为空的条件 font == rear 不同,所以可以区分空和满。
这也就是问题里说的,此时不满,所以我们还能再加入一个元素。
好了,现在满了吧,一个空都没有。那我们用公式表达一下现在的状态,rear == front ?
这不就和队列为空的条件重复了嘛,看着这个图,你还能写一个不同的表达式出来吗?不能,只能是 rear == front。
那当我们碰到 rear == front 的条件时,我们就没有区分队列是满的还是空的了。所以,循环队列一定要空一个位置。
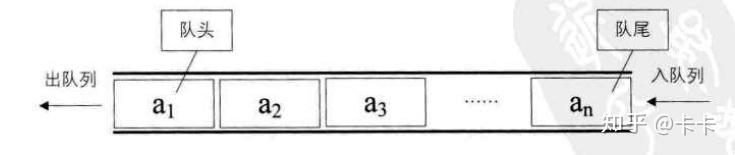
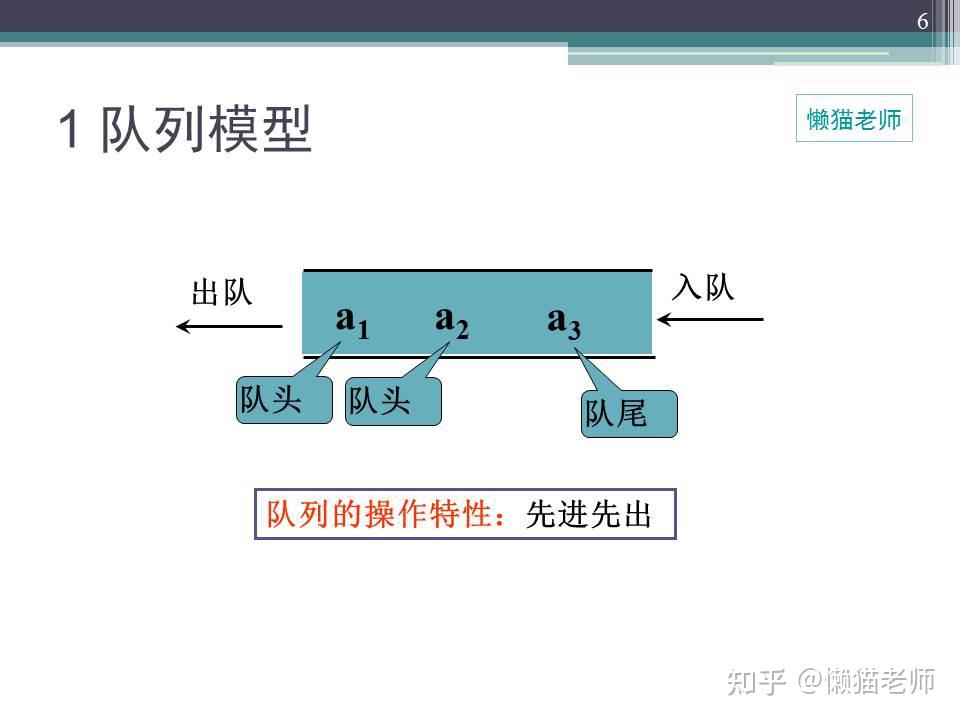
队列是一种先进先出(first in first out,FIFO)的线性表,是一种常用的数据结构。
它只允许在表的前端(front)进行删除操作,而在表的后端(rear)进行插入操作,和栈一样,队列是一种操作受限制的线性表。进行插入操作的端称为队尾,进行删除操作的端称为队头。队列中没有元素时,称为空队列。

队列有很多种,按照存储结构划分,有链式队列,循环队列,单向队列,双端队列。实现队列的方式也有很多种,如基于链式存储结构的链接队列(又称链队列),基于顺序存储结构的队列。
本文介绍基于数组(一种顺序存储结构)的循环队列的实现和一些基本操作,并用代码的形式讲解。
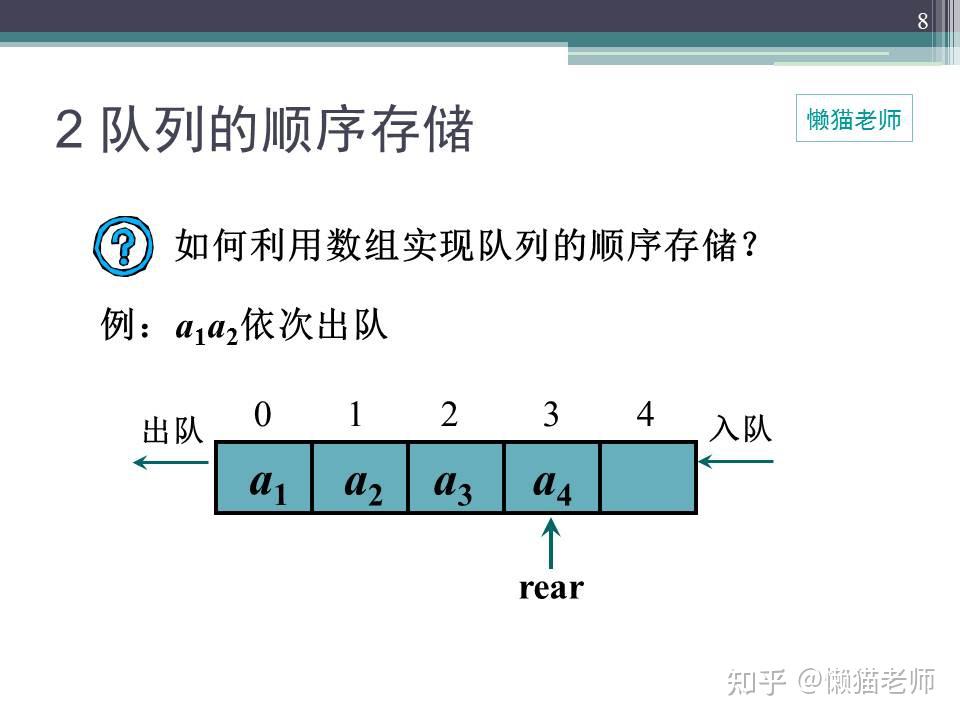
队列的顺序存储结构和顺序栈类似
在队列的顺序存储结构中,除了用一组地址连续的存储单元依次存放从队列头到队列尾的元素之外,还需要设置头尾两个指针front和rear,分别指示队列头元素及队尾元素的位置
我们规定
- 初始化建立空队列时,令front=rear=0
- 每当插入新的队尾元素时,“尾指针增1”
- 每当删除队头元素时,“头指针增1”
- 在非空队列中,头指针始终指向队列头元素,尾指针始终指向队列尾元素的下一个位置
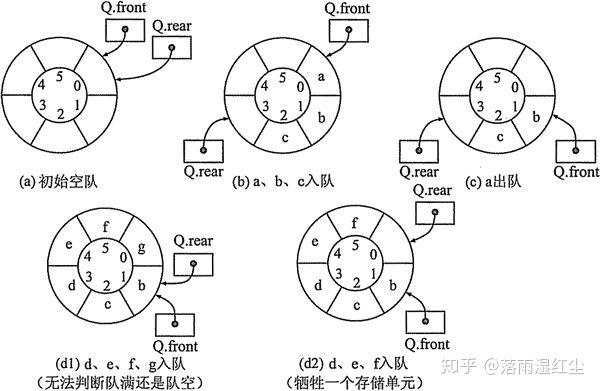
在入队和出队的操作中,头尾指针只增加不减小,致使被删除元素的空间永远无法重新利用,因此,尽管队列中实际的元素个数远远小于向量空间的规模,但也可能由于尾指针巳超出向量空间的上界而不能做入队操作,该现象称为假溢出
解决办法:将顺序队列臆造为一个环状的空间,称之为循环队列
以下代码,实现了一个可以保存学生学号(最长12位的字符串)循环队列,基于数组这种顺序存储结构,实现了它的初始化,出队,入队,队列销毁的操作
#include<stdio.h> #include<stdlib.h> #include<string.h> #define OK 1 #define NO 0 #define MAXSIZE 100 //循环队列结构 typedef struct LoopQueue{ char* base[MAXSIZE];//数据域由一个char*数组构成 int front;//队头索引,指向队列第一个数据所在位置 int rear; //队尾索引,指向队列最后一个数据后一个位置 }LoopQueue; //循环队列初始化。该循环队列基于数组,因此一旦声明一个LoopQueue变量 //其内部的base数组空间便自动分配,不需要自己分配 //只需初始化队头和队尾索引 int initLQueue(LoopQueue *Q){ Q->front = Q->rear =0; return OK; } //返回长度 int getLenth(LoopQueue *Q) { return (Q->rear - Q->front + MAXSIZE)%MAXSIZE; } //插入元素 int insertLQueue(LoopQueue *Q){ //这里牺牲掉了一个储存位置,用rear+1来和队头索引相比较以判断是否为满, //是为了和队列判空的条件相区分 //判断队列是否为满,未满则可以入队。如果已满,返回NO if((Q->rear+1)%MAXSIZE == Q->front) return NO; char * stuId = (char*)malloc(sizeof(12)); scanf("%s",stuId) ; Q->base[Q->rear] = stuId; Q->rear = (Q->rear+1)%MAXSIZE; return OK; } //元素出队 char* outLQueue(LoopQueue *Q){ //判断队列是否为空 if(Q->rear ==Q->front) return NULL; char * data_return = Q->base[Q->front]; Q->front = (Q->front+1)%MAXSIZE; return data_return; } //销毁队列,也是由于该循环队列基于数组,不需要分配内存 //只需重置队头和队尾索引即可 int destroyLQueue(LoopQueue *Q){ Q->front = Q->rear=0; return OK; } int main(){ // 初始化队列 LoopQueue Q; //定义一个选择变量 int choice; //元素插入个数 int num; //出队返回值 char* back; do{ printf("===========循环队列操作==========\n"); printf("1.初始化循环队列\n"); printf("2.元素入队\n"); printf("3.元素出队\n"); printf("4.销毁队列\n"); printf("0.退出\n"); printf("=====================\n"); printf("请输入您的选择:"); scanf("%d",&choice); switch(choice){ case 1: initLQueue(&Q)?printf("------------\n -->> 循环队列初始化成功\n------------\n"):printf("------------\n -->> 循环队列初始化失败\n------------\n"); break; case 2: printf("请输入插入元素个数:"); scanf("%d",&num); int i; for(i=0;i<num;i++){ printf(" 请输入第%d个学生的学号:",i+1); if(!insertLQueue(&Q))printf("------------\n-->> 第%d元素入队失败\n",i+1); } break; case 3: back = outLQueue(&Q); back? printf("------------\n 元素: %s 出队,还剩%d个元素\n",back,getLenth(&Q)):printf("------------\n队列为空,无法出队!\n") ; break; case 4: destroyLQueue(&Q)?printf("------------\n队列销毁成功!\n"):printf("------------\n队列销毁失败!\n"); break; case 0: printf("\n-->> 退出\n"); exit(0); break; default: break; } }while(choice); }以上代码经过调试,我自认为没有问题(鄙人才疏学浅,欢迎指正)
如果读者朋友们有疑问和更正,欢迎评论区补充和探讨
点击此处,可了解链队列的相关知识
队列是一种先进先出的线性表,简称FIFO。允许插入的一端称为队尾,允许删除的一端称为队头,如下图所示。
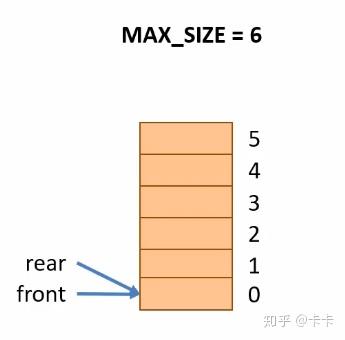
普通的顺序队列我们设置队头指针(front)和队尾指针(rear)来描述队列里的数据存储位置。初始两个指针都指向0号元素,如下图所示。
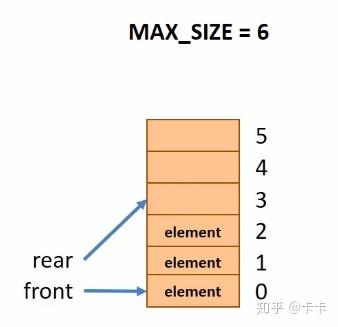
当入队时,rear指针向尾部移动,front指针则依旧指向首元素,如下图所示。
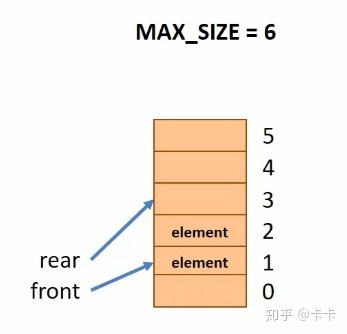
当出队时,front指针向下一个元素移动,释放出队元素,尾指针不变,入下图所示。
当出队入队次数足够多时,我们会发现队列不能入队了,但是却还有空间,如下图所示。
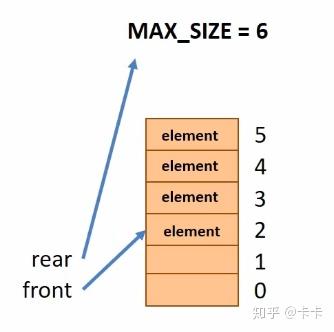
这就是所谓的队列“假溢出”现象,所造成得空间浪费,所以我们需要使用循环队列来解决。所谓循环队列,就是将队列的头尾相接,这样就不会出现上述问题。
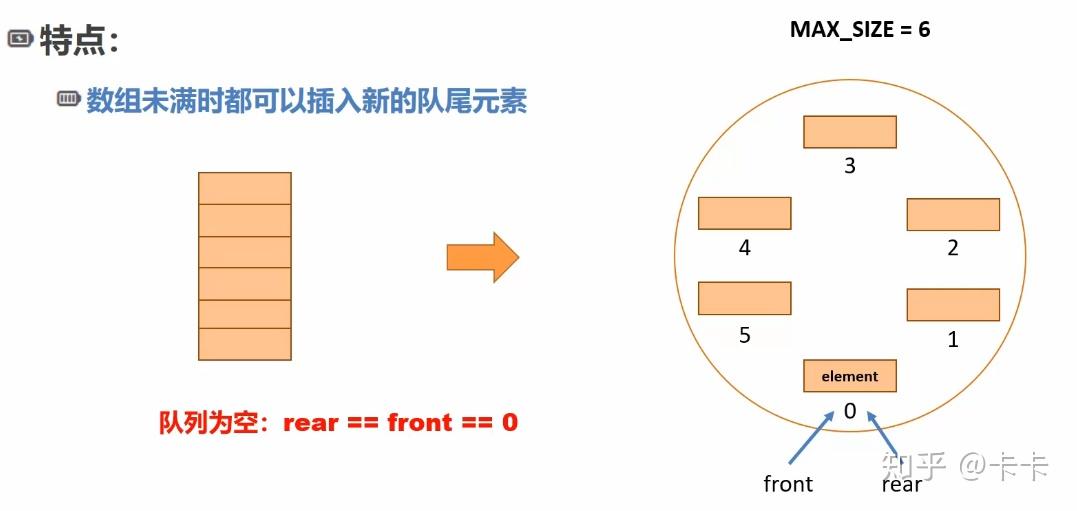
但是由于rear指针相当于头指针,是不指向元素的,所以我们实际的元素数量要比队列空间少一个,如下图所示,队列总长度为6,实际元素个数为5个,还有一个被rear指针使用。
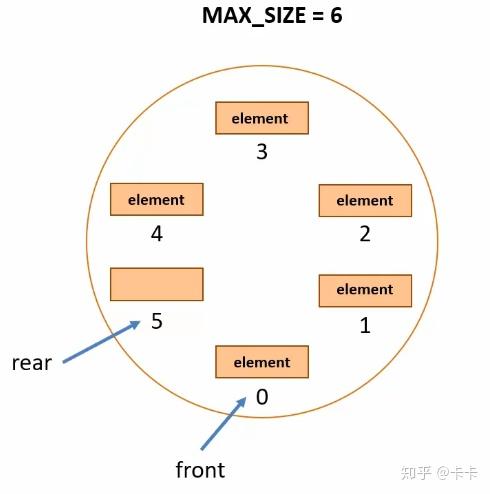
接下来我们实现循环队列的定义,结构中包含了数据元素、队头指针、队尾指针、队列长度。
/*循环队列结构*/ typedef struct SeqQueue { DataElement data[MAX_SIZE];//数据数组 int front; //队头指针(游标) int rear; //队尾指针(游标) int length; //队列长度 }SeqQueue;然后我们实现初始化函数,我们将分配内存空间在这里执行,并且初始化了数据元素和指针以及队列长度。
/*初始化队列*/ void InitSeqQueue(SeqQueue* seqQueue) { //动态创建一个队列空间 if (seqQueue == NULL) { seqQueue = (SeqQueue*)malloc(sizeof(SeqQueue)); } seqQueue->front = 0;//头指针为0 seqQueue->rear = 0; //尾指针为0 seqQueue->length = 0;//数组长度为0 }接下来实现入队(offer),入队规则是,从队尾入队元素,队尾指针指向(rear+1)%MAX_SIZE,队列长度加一。注意:我们这里返回一个int类型的状态。
#define STATE_OK 1 #define STATE_FAILD -1 typedef int State; /*入队*/ State OfferSeqQueue(SeqQueue* seqQueue, DataElement element) { //如果队列已满,则入队失败 if ((seqQueue->rear + 1) % MAX_SIZE == seqQueue->front) { return STATE_FAILD; } //入队操作 seqQueue->data[seqQueue->rear] = element;//赋值入队元素 seqQueue->rear = (seqQueue->rear + 1) % MAX_SIZE;//计算入队后尾指针的位置 seqQueue->length++;//入队后数组长度加一 return STATE_OK; }接着是出队操作(poll),出队规则是,从队头出队元素,队头指针指向(front+1)%MAX_SIZE,队列长度减一。我们这里还将出队元素另存返回了。
/*出队*/ State PollSeqQueue(SeqQueue* seqQueue, DataElement* element) { //如果队列为空,则出队失败 if ((seqQueue->rear == seqQueue->front)) { return STATE_FAILD; } //出队操作 *element = seqQueue->data[seqQueue->front];//另存出队元素 seqQueue->front = (seqQueue->front + 1) % MAX_SIZE;//计算出队后头指针的位置 seqQueue->length--;//出队后数组长度减一 return STATE_OK; }接下来我们测试下队列代码,先实现下打印函数。
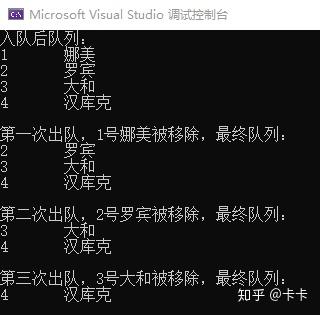
void PrintSeqQueue(SeqQueue* seqQueue) { for (int i = seqQueue->front; i < seqQueue->rear; i++) { printf("%d\t%s\n", seqQueue->data[i].id, seqQueue->data[i].name); } }然后实现测试函数,首先入队4个元素,接着连续出队3次,并打印出队元素信息。
DataElement dataArray[] = { { 1, "娜美"}, { 2, "罗宾"}, { 3, "大和"}, { 4, "汉库克"} }; void TestSeqQueue() { SeqQueue seqQueue; InitSeqQueue(&seqQueue); OfferSeqQueue(&seqQueue, dataArray[0]); OfferSeqQueue(&seqQueue, dataArray[1]); OfferSeqQueue(&seqQueue, dataArray[2]); OfferSeqQueue(&seqQueue, dataArray[3]); printf("入队后队列:\n"); PrintSeqQueue(&seqQueue); DataElement* pollElement = (DataElement*)malloc(sizeof(DataElement)); PollSeqQueue(&seqQueue, pollElement); printf("\n第一次出队,%d号%s被移除,最终队列:\n", pollElement->id, pollElement->name); PrintSeqQueue(&seqQueue); PollSeqQueue(&seqQueue, pollElement); printf("\n第二次出队,%d号%s被移除,最终队列:\n", pollElement->id, pollElement->name); PrintSeqQueue(&seqQueue); PollSeqQueue(&seqQueue, pollElement); printf("\n第三次出队,%d号%s被移除,最终队列:\n", pollElement->id, pollElement->name); PrintSeqQueue(&seqQueue); }编译运行,可以看到队列是先进先出,后进后出的。
上篇文章我们给大家介绍了数据结构与算法概述,主要通过经典的算法题来给大家讲解算法与数据结构的重要性,接着给大家介绍了数据结构和算法之间的关系,指出了实际编程中的问题,最后介绍了线性结构和非线性结构之间的几种常见的数据结构,今天的文章给大家介绍队列,在介绍队列之前首先给大家介绍稀疏数组。
在介绍正文内容之前给大家介绍一个python学习的课程,数据结构与算法是为了程序服务的,使我们程序更加的健壮,python比较好入门,我们在学习数据结构的同时也可以学习python,将其实现数据结构也是极好的。这门课程确实对我们编程能力还是python基础知识学习都有帮助,希望我们将python和数据结构与算法结合在一起,这样是最好的。希望大家共同进步。
我们在前面的文章中介绍过一个五子棋的程序,并且介绍了存盘退出和续上盘功能,也说明了实现其功能最为关键的就是稀疏数组。具体表示如下所示:
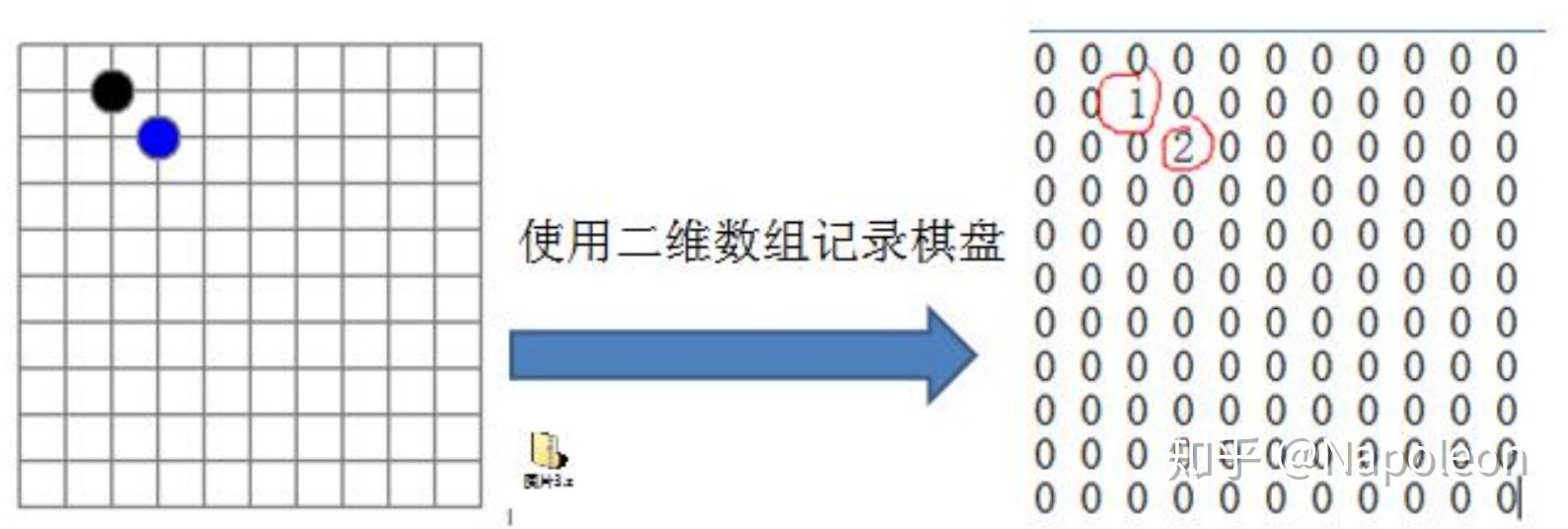
因为该二维数组的很多值是默认值为0,因此,记录了很多没有意义的数据——稀疏数组。
当一个数组中大部分元素为0,或者为同一个值的数组时,可以使用稀疏数组来保存该数组。稀疏数组的处理方法如下:
1)、记录数组一共有几行几列,有多少个不同的值
2)、把具有不同值的元素的行列及值记录在一个小规模的数组中,从而缩小的规模
使用稀疏数组,来保留类似前面的二维数组,例如棋盘、地图等等。并且把稀疏数组存盘,并且可以从新恢复原来的二维数组数,接下来给大家介绍二维数组转向稀疏数组的思路:
1、遍历原始的二维数组,得到有效数据的个数sum
2、根据sum就可以创建稀疏数组sparseArr int[sum+1][3]
3、将二维数组的有效数据存入到稀疏数组
接下来,给大家介绍稀疏数组转原始的二维数组的思路:
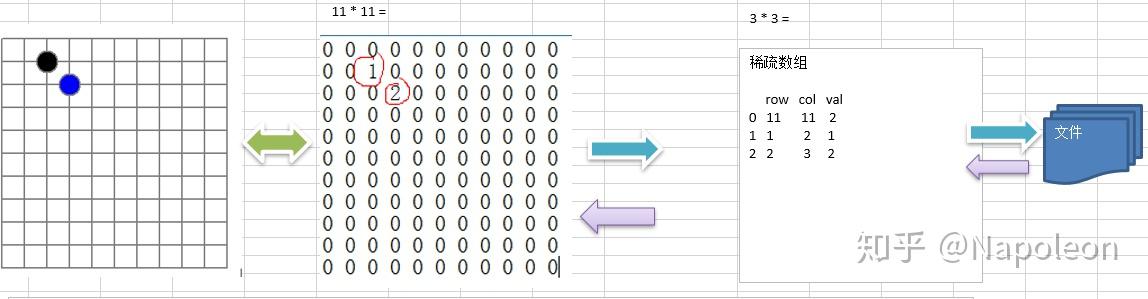
先读取稀疏数组的第一行,根据第一行的数据,创建原始的二维数组,比如下图中的chessArr2 = int[11][11]
在读取稀疏数组之后几行的数据,并赋给原始的二维数组即可;
具体如下图所示:
具体用java代码实现如下:
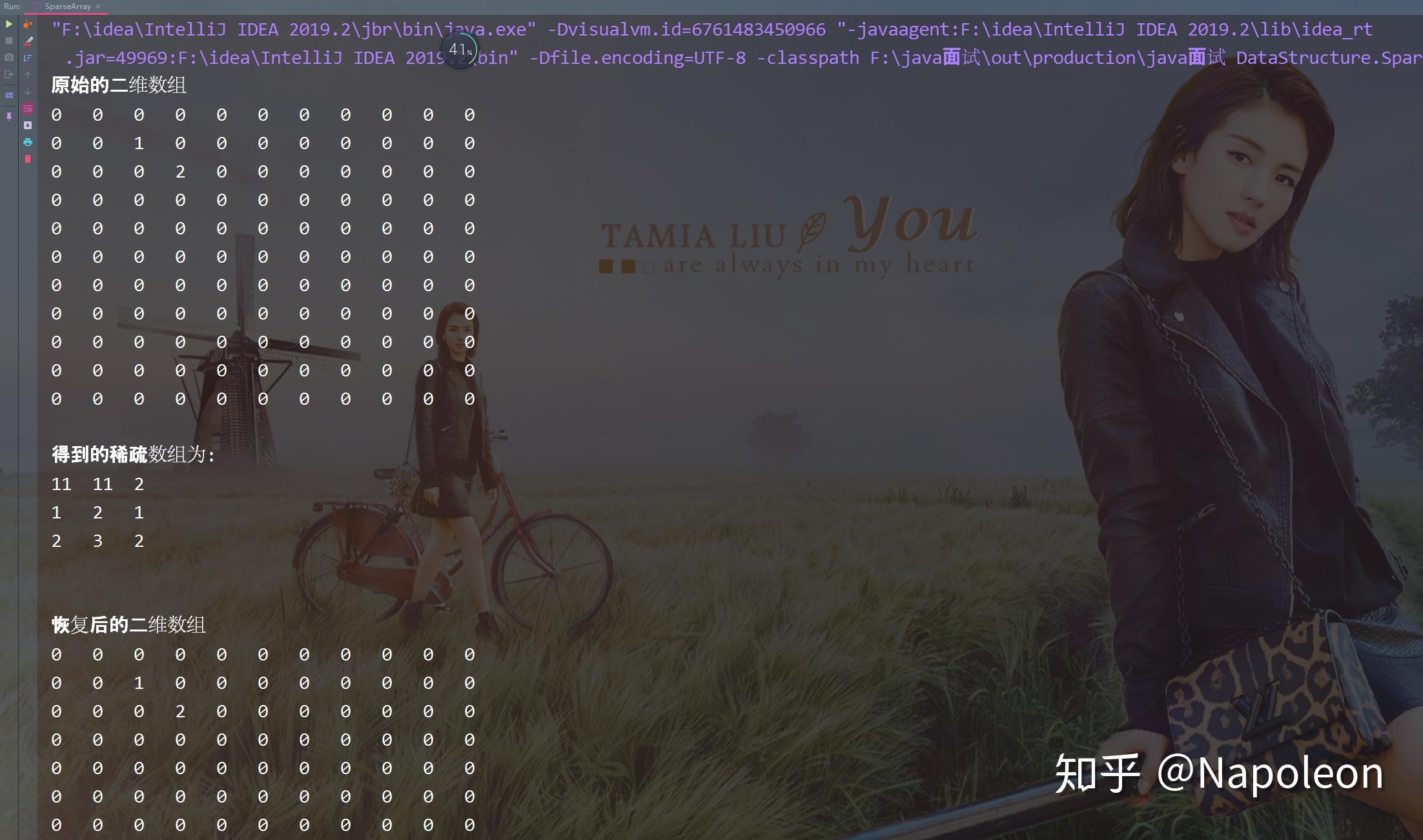
public class SparseArray { public static void main(String[] args) { // 创建一个原始的二维数组:11*11 // 0表示没有棋子,1表示黑子,2表示篮子 int chessArr1[][] = new int[11][11]; chessArr1[1][2] = 1; chessArr1[2][3] = 2; // 输出原始的二维数组 System.out.println ("原始的二维数组"); for(int[] row:chessArr1){ for (int data:row){ System.out.printf("%d\t", data); } System.out.println (); } // 将二维数组转换为稀疏矩阵 //1、遍历二维数组,得到非0的数据个数 int sum = 0; for(int i = 0; i < 11; i++){ for(int j = 0; j < 11; j++){ if(chessArr1[i][j] != 0){ sum++; } } } //2、创建对应的稀疏数组 int sparseArr[][] = new int[sum+1][3]; // 给稀疏数组赋值 sparseArr[0][0] = 11; sparseArr[0][1] = 11; sparseArr[0][2] = sum; //遍历二维数组,将非0值存放到sparseArr中 int count = 0; //用于记录第一个非0计数 for(int i = 0; i < 11; i++){ for(int j = 0; j < 11; j++){ if(chessArr1[i][j] != 0){ count++; sparseArr[count][0] = i; sparseArr[count][1] = j; sparseArr[count][2] = chessArr1[i][j]; } } } // 输出稀疏数组的形式 System.out.println (); System.out.println ("得到的稀疏数组为:"); for (int i = 0; i < sparseArr.length; i++){ System.out.printf("%d\t%d\t%d\t\n",sparseArr[i][0],sparseArr[i][1], sparseArr[i][2]); } System.out.println (); //将稀疏数组恢复成原始的二维数组 //先读取稀疏数组的第一行,根据第一行的数据,创建原始的二维数组 int chessArr2[][] = new int[sparseArr[0][0]][sparseArr[0][1]]; // 在读取稀疏数组后几行的数据(从第2行开始),并赋值给原始的二维数组即可 for(int i = 1; i < sparseArr.length; i++){ chessArr2[sparseArr[i][0]][sparseArr[i][1]] = sparseArr[i][2]; } //恢复输出后的二维数组 System.out.println (); System.out.println ("恢复后的二维数组"); for(int[] row:chessArr2){ for (int data:row){ System.out.printf("%d\t", data); } System.out.println (); } } }具体效果如下:
接下来,给大家第一个数据结构队列,它与栈是一起出现的,我们首先给大家介绍队列,栈放在下一篇文章进行介绍。其实,队列在日常生活中很常见,比如我们吃饭、购票排队就用到了队列。队列是一种有序列表,可以用数组或是链表来实现。并且遵循的是先入先出的原则。即先存入队列的数据,要先取出,后存入的要后取出。具体如下图所示:

接下来将介绍用数组来模拟队列进行相关的操作。其实队列本身有序列表,若使用数组结构来存储队列的数据,则队列数组的声明如下图,其中maxSize是该队列的最大容量。因为队列的输出、输入是分别从前后端来处理,因此需要两个变量front及rear分别记录队列前后端的下标,front会随着数据输出而改变,而rear则是随着数据输入而改变,具体如下图所示:

当我们将数据存入队列时称之为“addQueue”,“addQueue”的处理需要有以下两个步骤:
1、将尾指针往后移:rear+1,当front == rear【空】
2、若尾指针rear小于队列的最大下标maxSize-1,则将数据存入rear所指的数组元素中,否则无法存入数据。rear==maxSize-1【队列满】
具体代码实现如下:
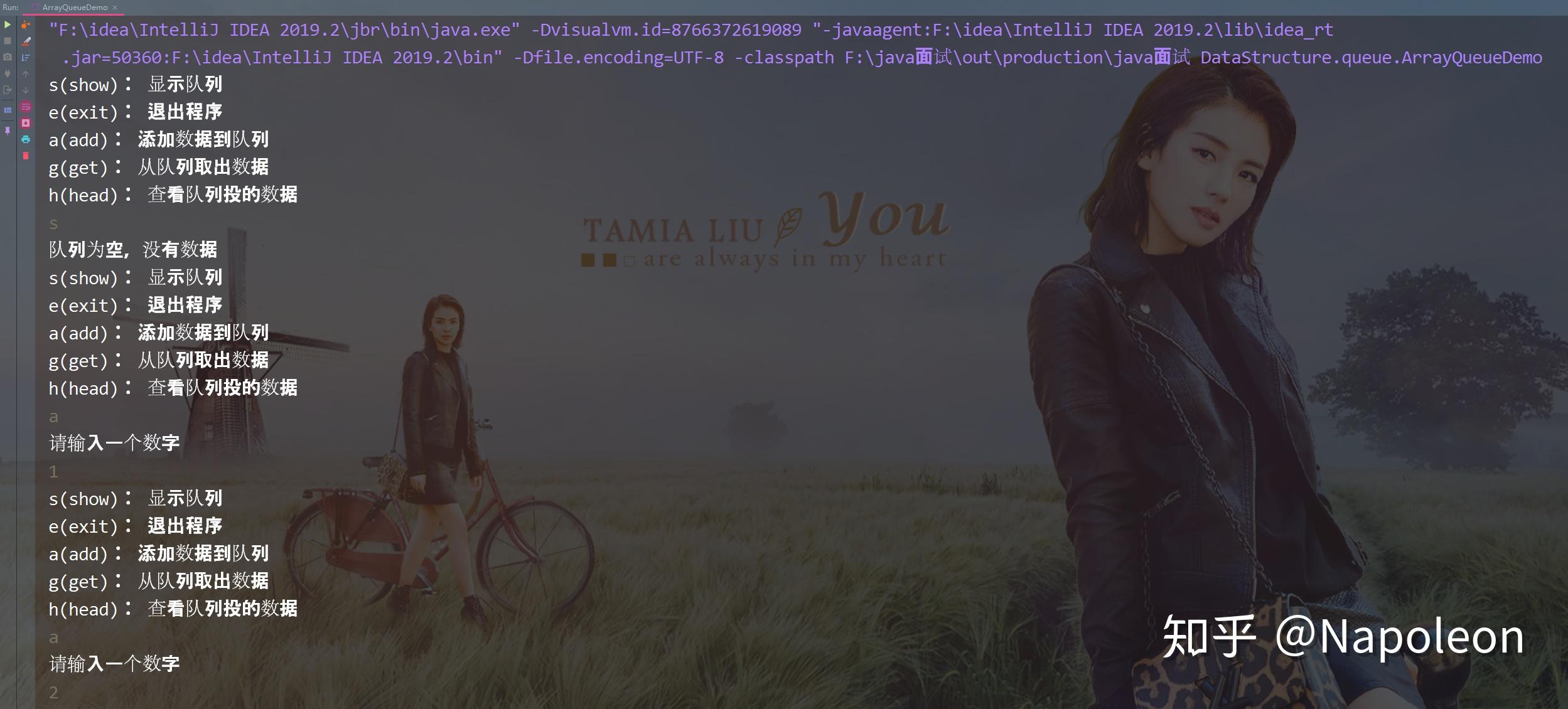
import java.util.Scanner; / * 用数组实现队列 */ public class ArrayQueueDemo { public static void main(String[] args) { // 创建一个队列 ArrayQueue arrayQueue = new ArrayQueue (3); char key = ' '; //接收用户输入 Scanner sc = new Scanner (System.in); boolean loop = true; // 输出一个菜单 while (loop){ System.out.println ("s(show): 显示队列"); System.out.println ("e(exit): 退出程序"); System.out.println ("a(add): 添加数据到队列"); System.out.println ("g(get): 从队列取出数据"); System.out.println ("h(head): 查看队列投的数据"); key = sc.next ().charAt (0); // 接收一个字符 switch (key){ case 's': arrayQueue.showQueue (); break; case 'a': System.out.println ("请输入一个数字"); int value = sc.nextInt (); arrayQueue.addQueue (value); break; case 'g': try{ int res = arrayQueue.getQueue (); System.out.printf ("取出的数据是%d\n", res); }catch (Exception e){ System.out.println (e.getMessage ()); } break; case 'h': try{ int res = arrayQueue.headQueue (); System.out.printf ("队列投的数据是%d\n", res); }catch (Exception e){ System.out.println (e.getMessage ()); } break; case 'e': sc.close (); loop = false; break; default: break; } } System.out.println ("程序退出"); } } // 使用数组模拟队列---编写一个ArrayQueue类 class ArrayQueue{ private int maxsize; // 表示数组最大容量 private int front; //对列头 private int rear; // 队列尾 private int[] arr; // 该数组用于存放数据,模拟队列 // 创建队列的构造器 public ArrayQueue(int arrMaxSize){ maxsize = arrMaxSize; arr = new int[maxsize]; front = -1; // 指向队列头部;front是指向队列头的前一个位置 rear = -1; // 指向队列尾,指向队列尾的数据(即就是队列最后一个数据) } // 判断队列是否为满 public boolean isFull(){ return rear == maxsize - 1; } / * * @return 判断队列是否为空 */ public boolean isEmpty(){ return rear == front; } / * 添加数据到队列 */ public void addQueue(int n){ // 判断对列是否为满 if (isFull ()){ System.out.println ("队列满,不可加入数据"); return; } rear ++; // 让rear后移 arr[rear] = n; } // 获取队列的数据,出队列 public int getQueue(){ // 判断对列是否为空 if(isEmpty ()){ //抛出异常 throw new RuntimeException ("队列为空,不可取数据"); } front++; return arr[front]; } // 显示队列所有数据 public void showQueue(){ // 遍历 if(isEmpty ()){ System.out.println ("队列为空,没有数据"); return; } for (int i = 0; i < arr.length; i++){ System.out.printf ("arr[%d] = %d\n", i, arr[i]); } } // 显示队列的头数据,注意:不是取出数据 public int headQueue(){ if(isEmpty ()){ throw new RuntimeException ("队列为空,没有数据"); } return arr[front+1]; } }执行效果如下:
通过上面对数组模拟队列的执行效果可知,目前的数组使用一次就不能用了,没有达到复用的效果。另外就是将这个数组使用算法,改进成一个环形队列,其中的取模用%。
我们前面介绍的数组模拟,现在给大家介绍数组模拟队列的优化,充分利用数组的特性,因此将数组看做是一个环形的。这里需要注意的是:通过取模的方式即可实现。以下作详细分析:
1):尾索引的下一个为头索引时表示队列满,即将队列容量空出一个作为约定,这个在做判断队列满的时候要注意(rear+1)%maxSize == front【满】
2):rear == front【空】
3):分析的示意图如下:
详细的思路如下:
- 1、
front变量的含义做一个调整:front就指向队列的第一个元素,也就是说arr[front]就是队列的第一个元素 - 2、
rear变量的含义做一个调整:rear指向队列的最后一个元素的后一个位置。因为希望空出一个空间作为约定。rear的初始值为0 - 3、当队列满时,条件是
(rear+1)%maxsize=front【满】 - 4、当队列为空的条件,
rear == front【空】 - 5、按照我们的分析,队列中有效的数据的个数为
(rear + maxsize - front) % maxsize// rear = 1, front = 0 - 6、通过上面的分析,我们可以在原来的队列上修改得到一个环形队列。
具体用代码实现如下:
import java.util.Scanner; / * 用数组实现循环队列 */ public class CircleArrayQueue { public static void main(String[] args) { System.out.println ("测试数组模拟环形队列"); // 创建一个队列 CircleArray circlequeue = new CircleArray (4); char key = ' '; //接收用户输入 Scanner sc = new Scanner (System.in); boolean loop = true; // 输出一个菜单 while (loop){ System.out.println ("s(show): 显示队列"); System.out.println ("e(exit): 退出程序"); System.out.println ("a(add): 添加数据到队列"); System.out.println ("g(get): 从队列取出数据"); System.out.println ("h(head): 查看队列投的数据"); key = sc.next ().charAt (0); // 接收一个字符 switch (key){ case 's': circlequeue.showQueue (); break; case 'a': System.out.println ("请输入一个数字"); int value = sc.nextInt (); circlequeue.addQueue (value); break; case 'g': try{ int res = circlequeue.getQueue (); System.out.printf ("取出的数据是%d\n", res); }catch (Exception e){ System.out.println (e.getMessage ()); } break; case 'h': try{ int res = circlequeue.headQueue (); System.out.printf ("队列投的数据是%d\n", res); }catch (Exception e){ System.out.println (e.getMessage ()); } break; case 'e': sc.close (); loop = false; break; default: break; } } System.out.println ("程序退出"); } } class CircleArray{ //front变量的含义做一个调整:front就指向队列的第一个元素 //front的初始值为0 private int maxsize; // 表示数组最大容量 private int front; //对列头 private int rear; // 队列尾 private int[] arr; // 该数组用于存放数据,模拟队列 public CircleArray(int arrMaxsize){ maxsize = arrMaxsize; arr = new int[maxsize]; } // 判断队列是否为满 public boolean isFull(){ return (rear + 1) % maxsize == front; } public boolean isEmpty(){ return rear == front; } //添加数据 public void addQueue(int n){ // 判断对列是否为满 if (isFull ()){ System.out.println ("队列满,不可加入数据"); return; } //直接将数据加入 arr[rear] = n; // 将rear后移,必须取模 rear = (rear+1)%maxsize; } // 获取队列的数据,出队列 public int getQueue(){ // 判断对列是否为空 if(isEmpty ()){ //抛出异常 throw new RuntimeException ("队列为空,不可取数据"); } // 这里需要分析出front是指向队列的第一个元素 //1、先把front的对应的值保存到临时的变量 //2、将front后移,考虑取模 //3、将临时保存的变量返回 int value = arr[front]; front = (front + 1) % maxsize; return value; } // 显示队列所有数据 public void showQueue(){ // 遍历 if(isEmpty ()){ System.out.println ("队列为空,没有数据"); return; } // 从front开始, 遍历多少个元素即可 for (int i = front; i < front+size (); i++){ System.out.printf ("arr[%d] = %d\n", i % maxsize, arr[i % maxsize]); } } // 求出当前队列的有效数据个数 public int size(){ return (rear + maxsize - front) % maxsize; } // 显示队列的头数据,注意:不是取出数据 public int headQueue(){ if(isEmpty ()){ throw new RuntimeException ("队列为空,没有数据"); } return arr[front]; } }具体执行的效果如下:
上篇文章给大家介绍了数据结构与算法概述,主要为大家介绍了本文给大家介绍了数据结构与算法的基本概念,主要通过经典的算法题来给大家讲解算法与数据结构的重要性,接着给大家介绍了数据结构和算法之间的关系,指出了实际编程中的问题,最后介绍了线性结构和非线性结构之间的几种常见的数据结构。今天的文章给大家介绍数据结构中的第一个算法——队列,首先给大家介绍了稀疏数组的相关内容,包括稀疏数组的基本知识以及想换转换的思想以及用代码实现,最后就是介绍了队列的相关内容,还有就是介绍了用数组进行模拟队列的相关操作,又将其优化,介绍了循环队列的思路分析及其实现。其实数据结构与算法是特别重要的,在编程中有至关重要的地位,因此,需要我们特别的掌握。生命不息,奋斗不止,我们每天努力,好好学习,不断提高自己的能力,相信自己一定会学有所获。加油!!!
文章首发于微信公众号:小K算法
有一只蚂蚁出去寻找食物,无意中进入了一个迷宫。蚂蚁只能向上、下、左、右4个方向走,迷宫中有墙和水的地方都无法通行。这时蚂蚁犯难了,怎样才能找出到食物的最短路径呢?
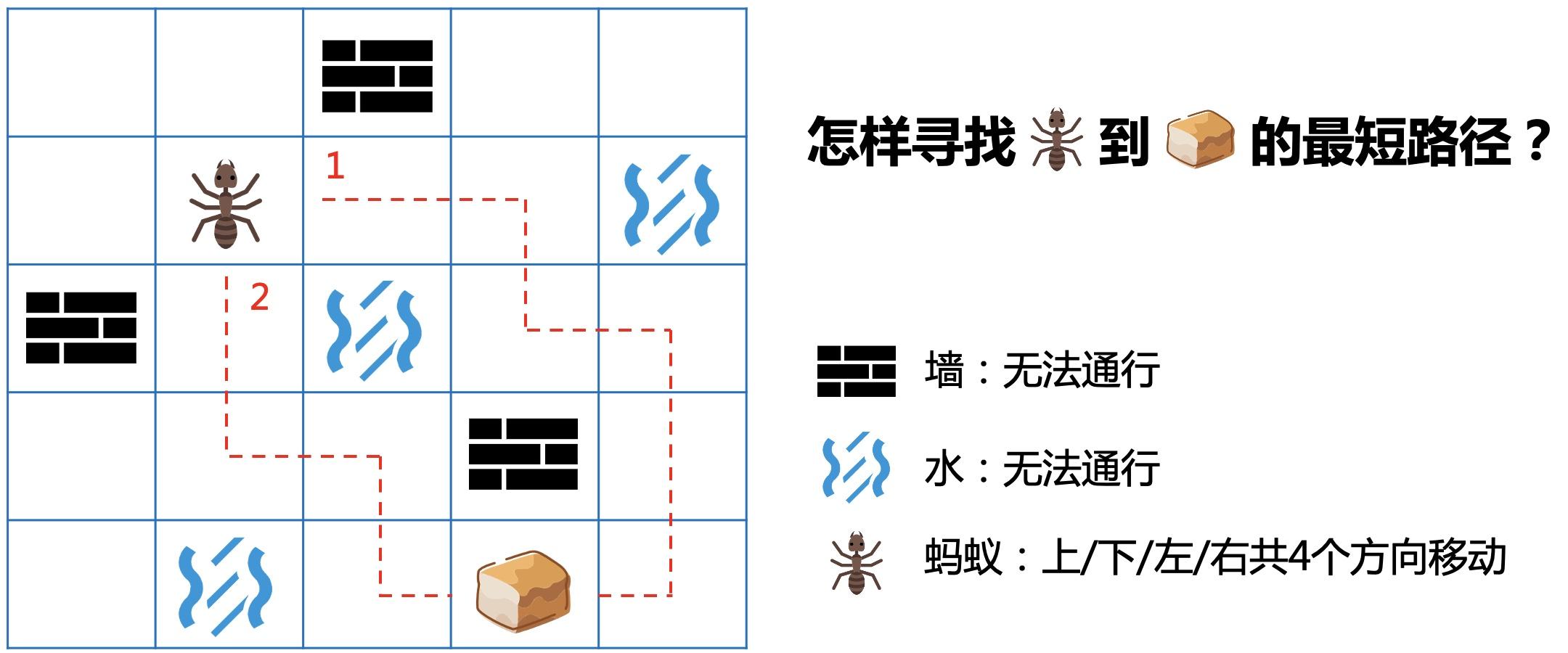
蚂蚁在起点时,有4个选择,可以向上、下、左、右某一个方向走1步。
如果蚂蚁走过了一段距离,此时也依然只有4个选择。
当然要排除之前走过的地方(不走回头路,走了也只会更长)和无法通过的墙和水。
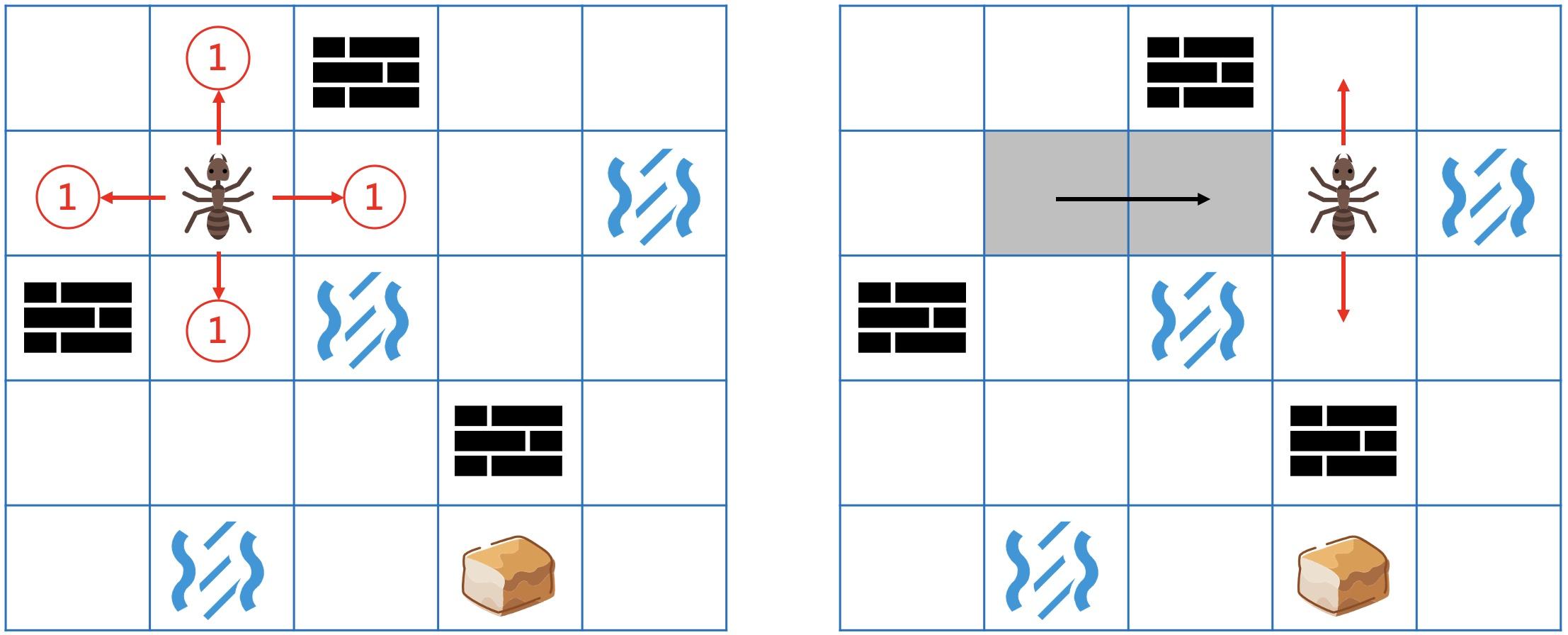
蚂蚁想,还好我会影分身。如果每一步都分身成4个蚂蚁,向4个方向各走1步,这样最先找到食物的肯定就是最短的路径了(因为每一步都把能走的地方都走完了,肯定找不出更短的路径了)。
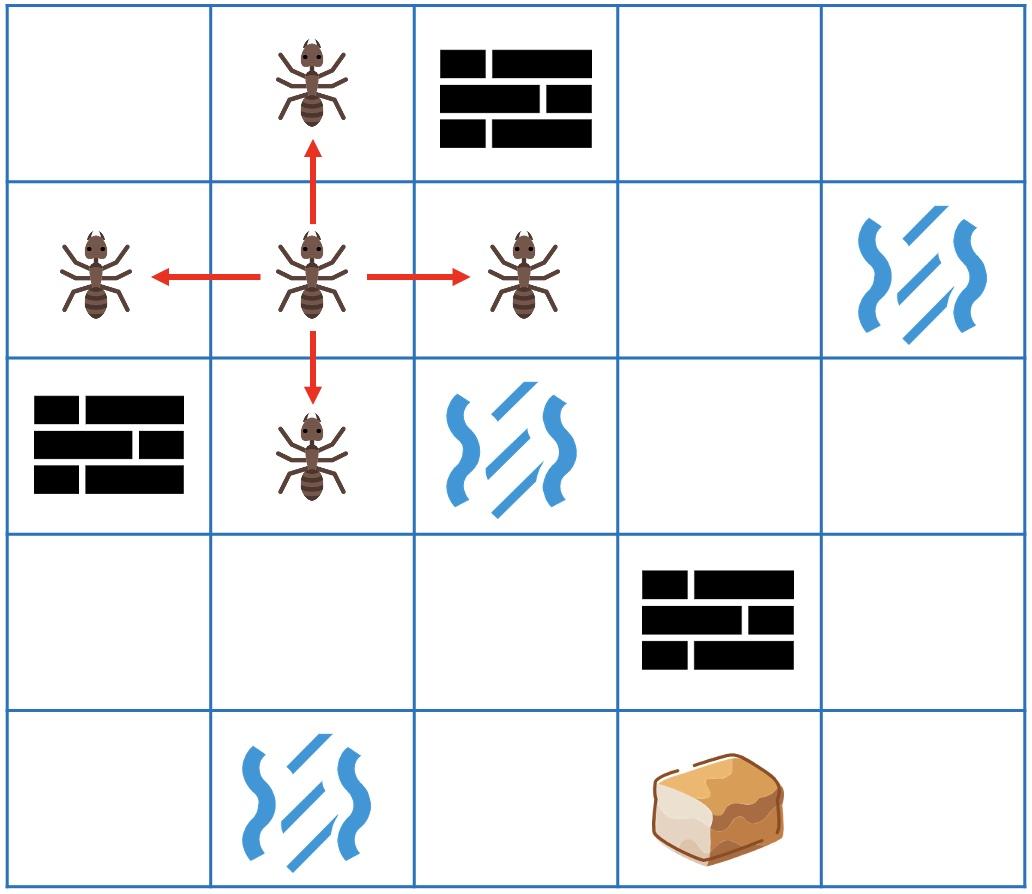
而且还能看出,第1步会到达所有到起点距离为1的地方,第2步也会到达所有距离为2的地方。 如此类推,第n步会覆盖所有到起点最短距离为n的地方。
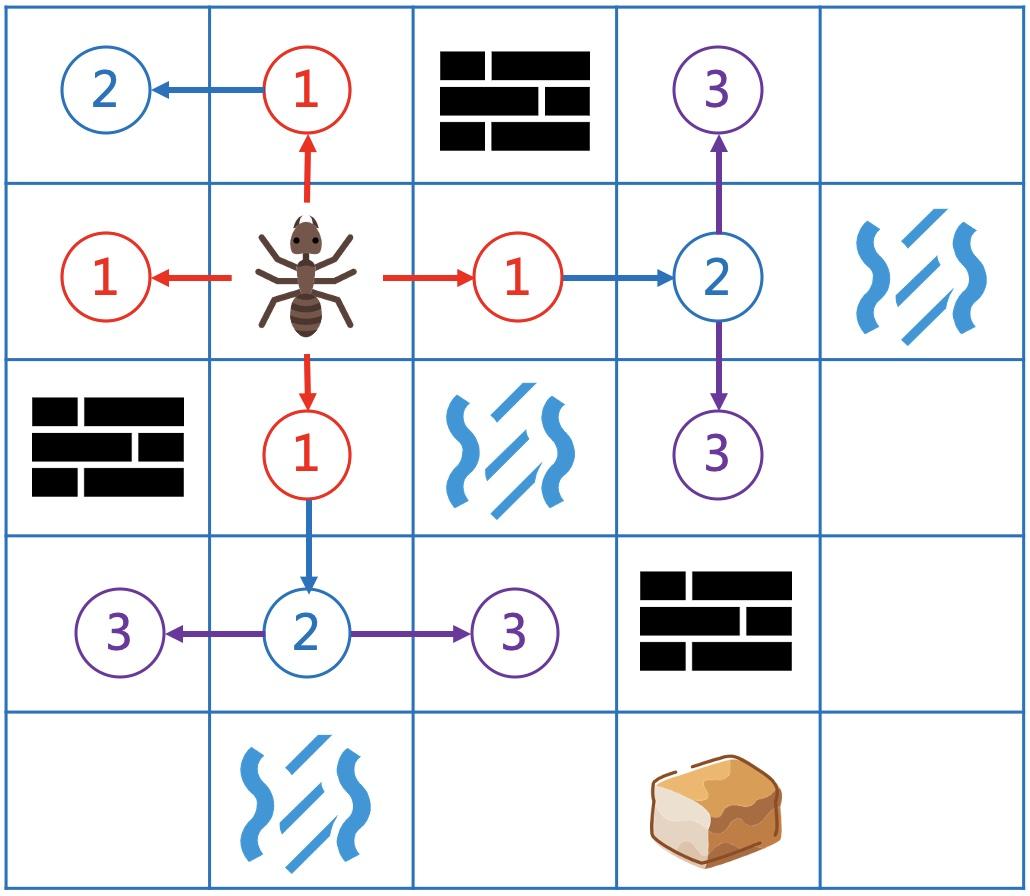
把迷宫地图放在二维数组中,能通行的地方为0,墙和水的地方为负数。

每一步向4个方向走,可以通过当前坐标 加上一个方向向量。
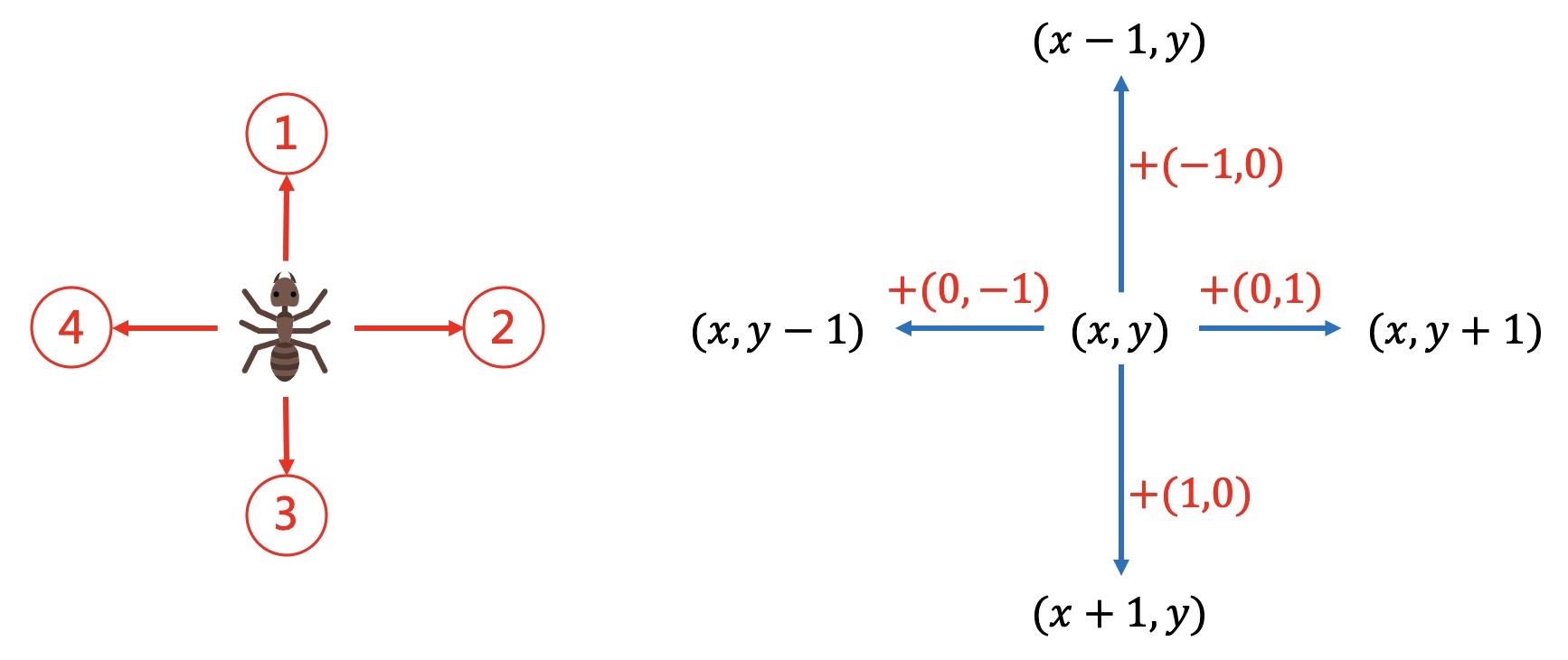
这个其实就是宽度优先搜索(BFS)的思想。
又称广度优先搜索,优先向四周扩展子节点,是最简便的图的搜索算法之一,一般通过队列来实现。
是一种特殊的线性表,它只允许在表的前端进行删除操作,而在表的后端进行插入操作,即先进先出。
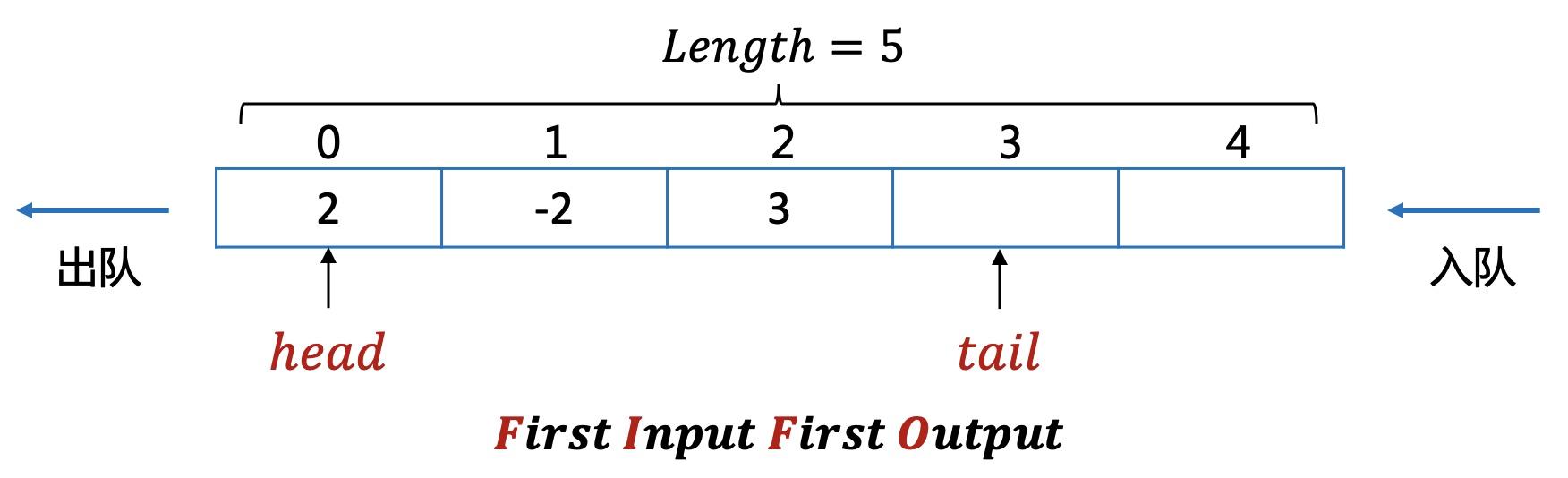
队列一般通过数组实现,对该数组增加一些操作上的限制。
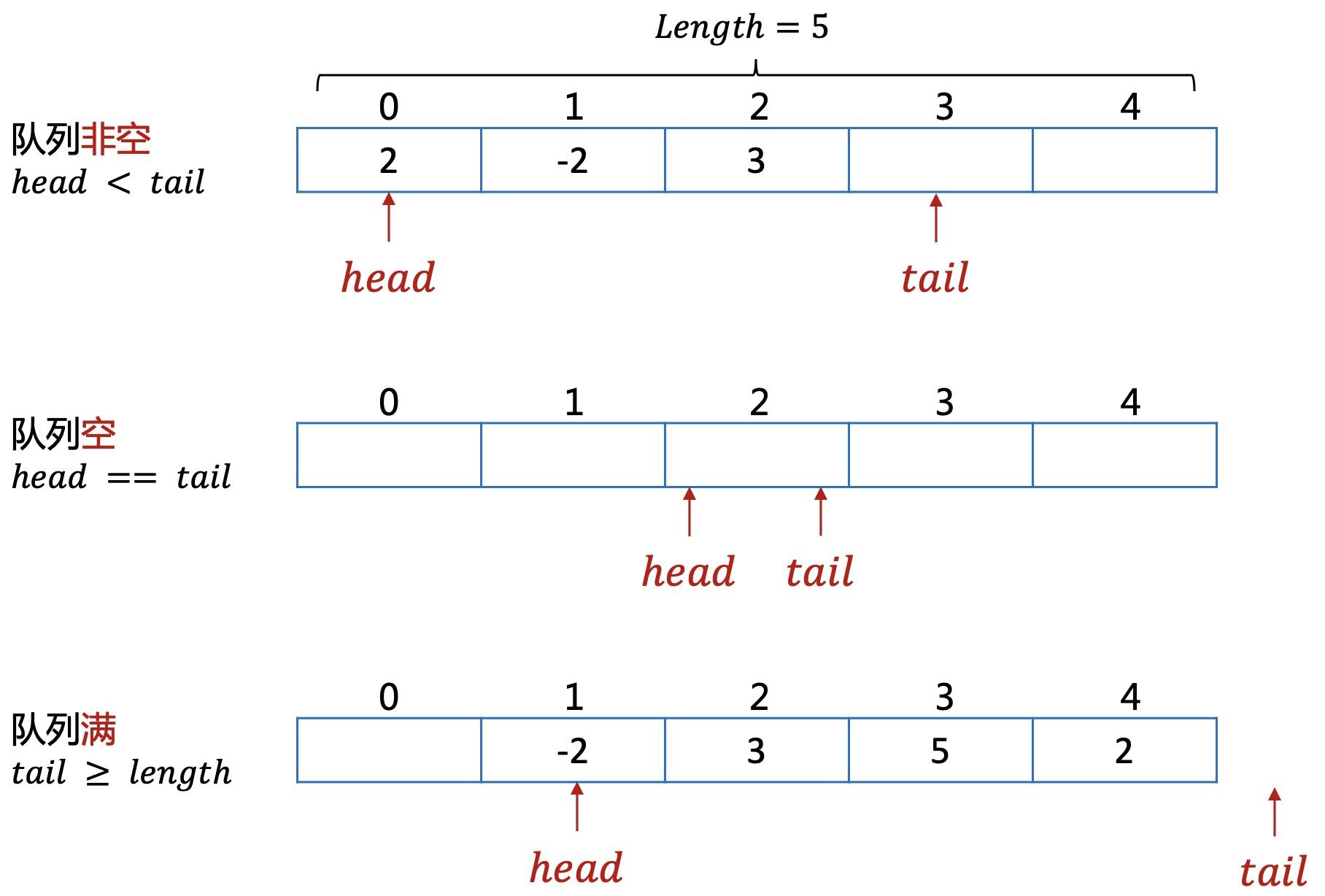
但上面的实现有一些缺陷,当队列满时,也就是tail指针移动到队尾,这时就无法再插入数据,但前面的元素已经出队了,可能还有空缺的位置。
为了能高效利用空间,对该队列增加一点改进,也就是循环队列的产生。
把队列想象成一个首尾相接的环形。
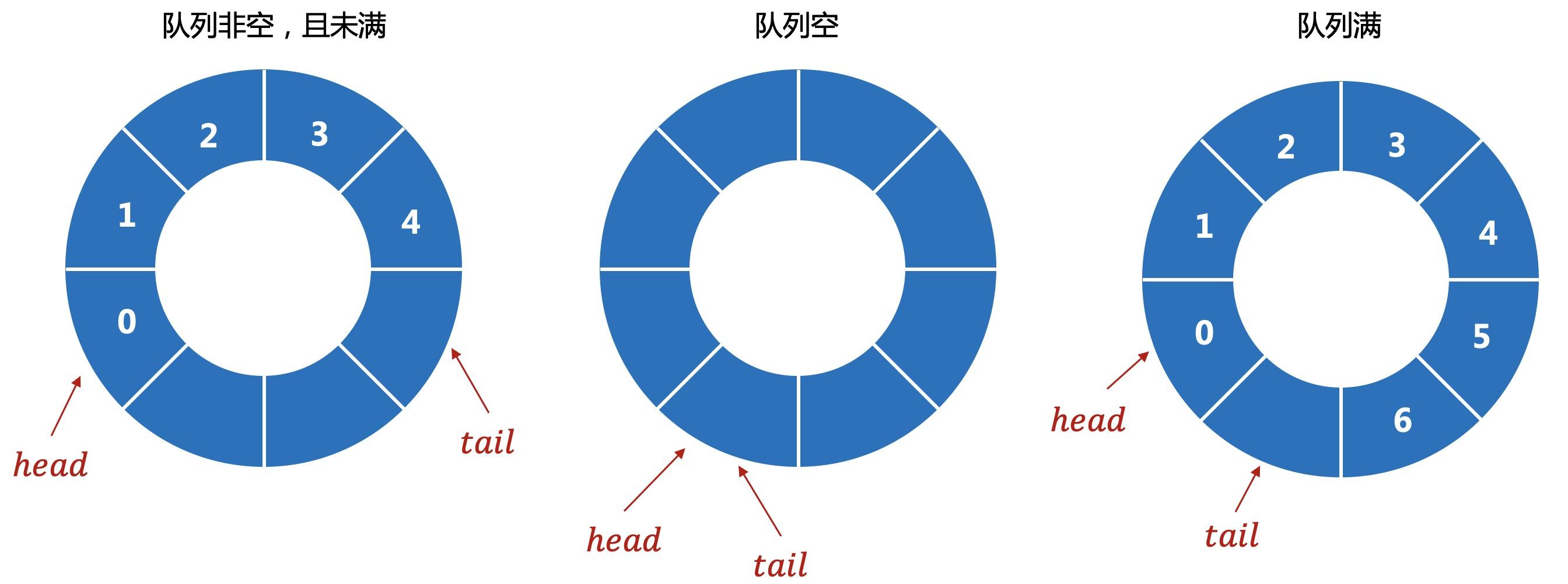
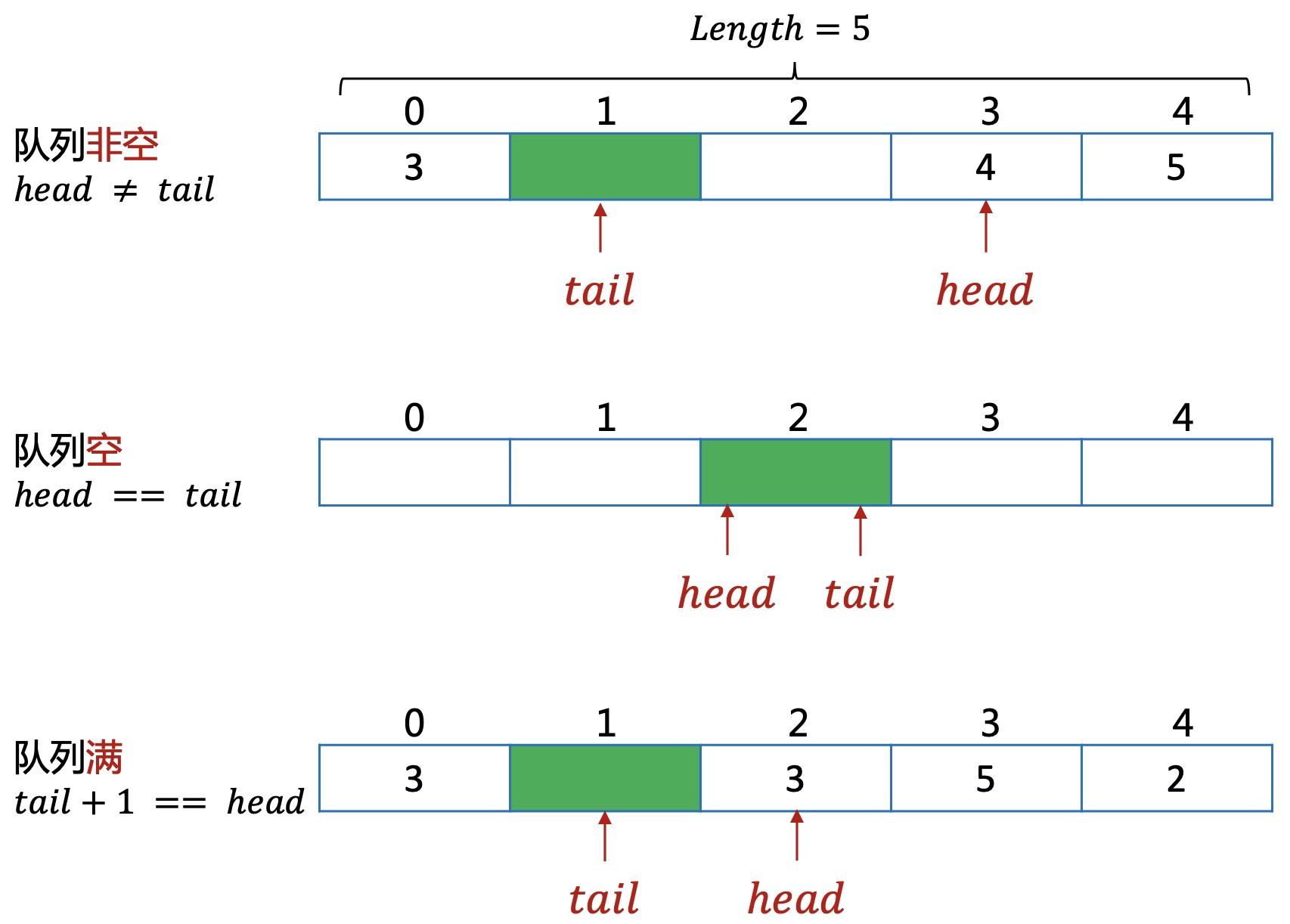
数组实现,需要多预留一个空间。如果head=tail时,无法判断是队空还是队满,所以占用一个空间,通过tail+1与head的关系来判断是否队满。
实现步骤如下:
- 将起点加入队列。
- 从队首取出一个节点,通过该节点向4个方向扩展子节点,并依次加入队尾。
- 重复以上步骤,直至队空或已找到目标位置。
回归迷宫问题,到起点的距离为1,2,3...的点会依次入队。
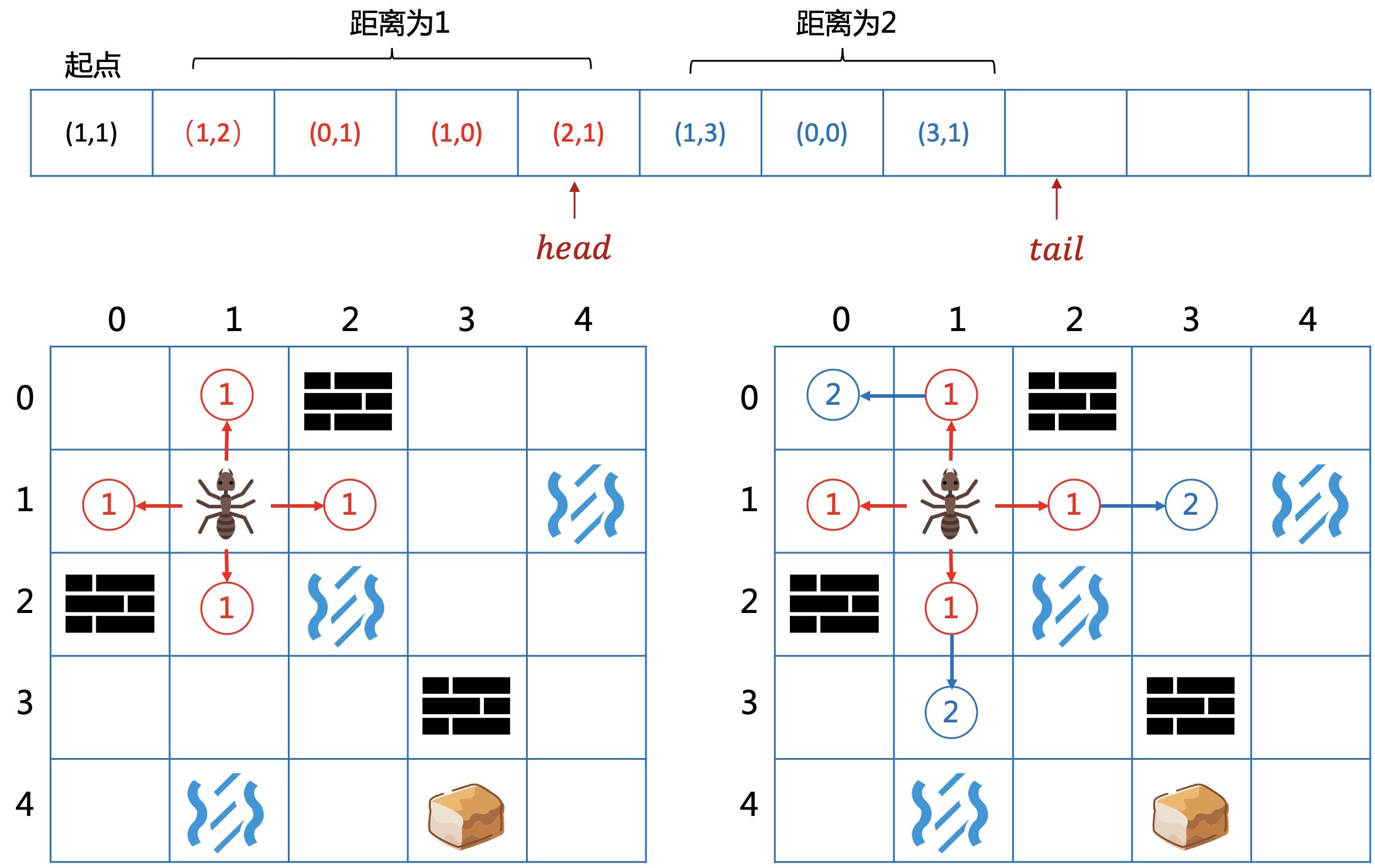
当head指针遍历到距离为2的点时,向4周扩展距离为3的节点,并继续入队。
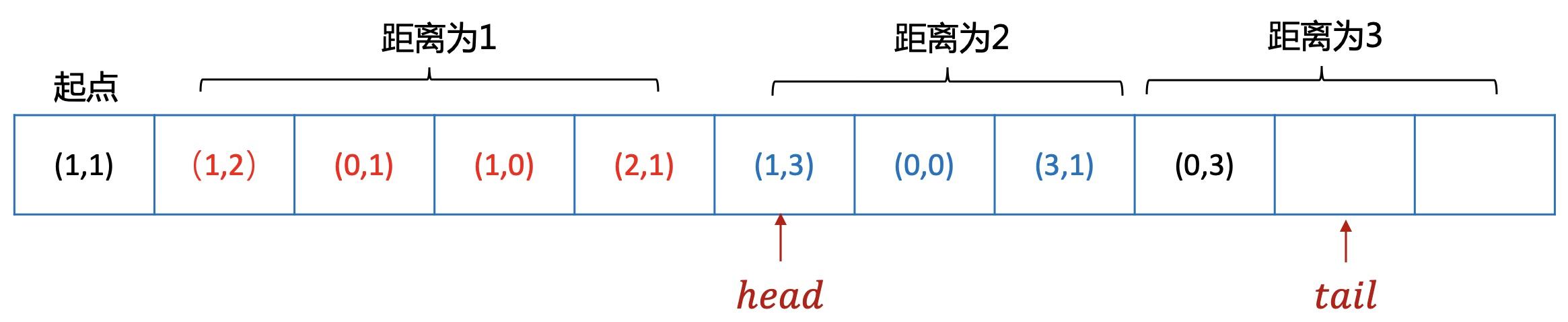
// 方向向量 const int direction[4][2] = {{0, 1}, {-1, 0}, {0, -1}, {1, 0}}; const int MAXM = 100, MAXN = 100, QUEUE_LENGTH = 5; // 队列中的节点 struct Node { int x, y, distance; Node() {} Node(int xx, int yy, int d) : x(xx), y(yy), distance(d) {} }; int n, m, step = 0, map[MAXM][MAXN], visit[MAXM][MAXN]; Node start, target; void bfs() { Node queue[QUEUE_LENGTH]; int head = 0, tail = 1; queue[0] = Node(start.x, start.y, 0); visit[start.x][start.y] = 0; while (head != tail) { int x = queue[head].x; int y = queue[head].y; int distance = queue[head].distance; head = (head + 1) % QUEUE_LENGTH; for (int i = 0; i < 4; ++i) { int dx = x + direction[i][0]; int dy = y + direction[i][1]; if (dx >= 0 && dx < m && dy >= 0 && dy < n && visit[dx][dy] == -1 && map[dx][dy] >= 0) { // 表示从i方向走过来的,方便后续回溯路径 visit[dx][dy] = i; if (dx == target.x && dy == target.y) { cout << "已到目标点,最短距离为" << distance + 1 << endl; step = distance + 1; return; } if ((tail + 1) % QUEUE_LENGTH == head) { cout << "队列满" << endl; return; } // 新坐标入队 queue[tail] = Node(dx, dy, distance + 1); tail = (tail + 1) % (QUEUE_LENGTH); } } } } void printPath() { int x, y, d, path[MAXM][MAXN] = {0}; for (int i = 0; i < m; ++i) { for (int j = 0; j < n; ++j) { path[i][j] = -1; } } x = target.x; y = target.y; path[start.x][start.y] = 0; // 路径回溯 while (!(x == start.x && y == start.y)) { path[x][y] = step--; d = visit[x][y]; x -= direction[d][0]; y -= direction[d][1]; } // 路径打印 for (int i = 0; i < m; ++i) { for (int j = 0; j < n; ++j) { if (path[i][j] >= 0) { cout << path[i][j]; } else { cout << "-"; } } cout << endl; } } int main() { cin >> m >> n; for (int i = 0; i < m; ++i) { for (int j = 0; j < n; ++j) { cin >> map[i][j]; visit[i][j] = -1; } } cin >> start.x >> start.y >> target.x >> target.y; bfs(); if (step > 0) printPath(); return 0; } 输入数据: 5 5 0 0 -1 0 0 0 0 0 0 -2 -1 0 -2 0 0 0 0 0 -1 0 0 -2 0 0 0 1 1 4 3 输出: 已到目标点,最短距离为5 路径打印: ----- -0--- -1--- -23-- --45- - 队列的定义:
队列是一种操作受限制的线性表,有着“先进先出,后进后出”的特点;就像地铁站,一整个队只能向前移动,所有的人只能从入站口进入,从出站口出去。在队列中,这个入站口就被称为“队尾(rear)”,可以从此处进入队列,称为“入队”;出站口就被称为“队首(front)”,可以从此退出队列,被称为“出队”。
2. 队列的状态:
在不断入队、出队时,队列将会出现以下几种特殊状态:
①队满:队列的空间都被占用。
②队空:队列中没有任何元素。
③上溢:当队满时却还要入队。
④下溢:当队空时却还要出队。
3. 队列的实现:
我们可以用链表或数组来实现一个队列,但一般使用后者。队列中还有一种特殊的队列,叫做“循环队列”,稍后会讲解;现在我们先用数组来实现一个队列 q [ max + 1 ] 。首先,我们需要用两个位置指针,分别记录队首和队尾的位置,被称为“队首指针(front)”和“队尾指针(rear)”。注意,为了简化操作,我们约定 front 指向队列首元素的前一个位置, rear 就指向队列最后一个有效元素的位置。
即队列可以用三个变量来描述:队首指针 (front),队尾指针 (rear),最多可容纳的元素个数 (max)。一个队列 q ,可利用的就是 q[0] 到 q[max-1] 这几个元素。
注意:最后一个元素是 q[max-1] 。
4. 队列的操作:
十六字口诀:“判满入队,判空出队。求好长度,取首元素。”
①队列初始化(clear):
初始化即表示队列为空,没有任何元素,也就是 front = 0、rear = 0。
void clear(int q[], int &front, int &rear, int &max){ front=rear=0; } ②判满入队(push):
入队之前,我们首先要判满来防止“下溢”。队列为满,即为队尾指针指向最后一个空间。
int full(int q[], int front, int rear, int max){ return rear == max; } 我们想要将一个元素 x 加入队列,只能将它加在队列的最后一个元素的后面(队列的特性)。故我们要把队尾指针向后移动一位,重新指向加入后的最后一个元素的位置,然后再将这一个元素加入队列。
void push(int q[], int &front, int &rear, int &max, int x){ if( !full(q[], front, rear, max) ) q[++rear] = x ; } ③判空出队(empty + pop):
出队之前,我们首先要判空来防止“下溢”。队列为空,意味着没有任何元素,也就是队尾指针指向队首;故只要判断队首指针和队尾指针是否相等。
int empty(int q[], int front, int rear, int max){ return front == rear; } 同理,如果一个队列不为空,想使一个元素出队,我们只能使队首的元素被删去。那么只需将队头指针向后移动一位,重新指向后一个元素的前一个位置,使得后一个元素成为队首即可。
void pop(int q[], int &front, int &rear, int &max){ if(!empty(q[], front, rear, max)) ++front; } ④求好长度(size):
队列的长度是就是队首指针和队尾指针之间的元素个数(包括队尾指针),故只需要用队尾指针减去队首指针,剩下的就是队列的有效长度。
int size(int q[], int front, int rear, int max){ return rear - front; } ⑤取首元素(get_front):
因为队首指针指向的是首元素前一个位置,所以队首指针 + 1 就是首元素的位置。
int get_front(int q[], int front, int rear, int max){ return q[ front + 1 ]; } 5. 循环队列
(1). 循环队列的产生:
我们发现,在进行入队和出队操作时,都只能把队首指针或队尾指针向后一个位置移动。多次操作之后,队尾指针就有可能指向数组的最后一个元素 q[ max ] ,此时按照之前的判定,我们会说这个队列满了,不能再添加元素了;但是队首指针前面明明还有一堆废弃不用的“空闲区”啊!这么多空间被白白地浪费,我们当然不允许。解决这种“假溢出”,通常就会有两种方案:第一种,每次出队时,都把元素整体向前移动一位,这样就会用上所有的空间——但是缺点就在于,时间复杂度高了不少。那么,有没有不浪费空间又不增加时间的解决方案呢?这一种方法,就是我们所说的循环队列——把队列手动弯起来,首位相接,使得 q[ max ] 的下一个元素是 q[ 0 ] ,把“空闲区”当做可以利用的区域。
(2). 循环队列的实现:(注意,这里的加减都是指循环意义下的加减)
还记得十六字口诀吧:“判满入队,判空出队。求好长度,取首元素。”我们慢慢来。
①初始化:
front = rear = 0; ②判空与判满:
判空:我们还是使用相同的方法,即:
return front == rear ; 判满:试想一下,我们不动 front (=0) ,一直向队列中添加元素,直到 rear = max - 1。这时候如果再添加一个元素,它会被储存在 q[0] 的位置,也就是 front 所在的位置,按照之前“队满”的定义,整个队列才是满的。但如果是那样的话,我们发现,判断队满的条件变成了 front == rear ,这不和判空的条件一样了吗?难道就没办法判满了吗?不,我们可以改定义!如果我们把“队满”的条件放宽一点,弃用队首指针所在的那一个位置的空间,使得“队满”在循环队列中的定义变成“最后一个有效元素的下一个元素是队首指针(而不是第一个有效元素)”,也就是“队尾指针在循环意义下加一等于队首指针”,就可以避免这个问题。什么叫做“队尾指针在循环意义下加一等于队首指针”呢?就是求队尾指针加一后,如果比max大,就求比max大了多少;否则,就是正常的加一。这个过程,我们可以用模运算(取余)解决,即:
return (rear + 1) % max == front; 如这时若 rear = max-1 ,front = 0, 便可判断队列已满。
③入队与出队
入队:我们在对普通队列进行入队操作时,在判满后,其实是分成了两步来做。第一步,求出当前 rear 的下一个位置,以供插入元素;第二步,插入 x 到后面,并改变 rear 的指向。在循环数组中,操作也基本相同;不过我们在判满时就说过,加一要用模运算。即:
q[ rear = (rear + 1) % max ] = x ; 出队:同样地,我们在循环意义下来对 front 进行加一:
front = (front + 1) % max ; ④求长度 :
在普通队列中,我们是怎么队列的长度的?就是从 front 的下一个位置开始一直数,数到 rear 为止;在循环队列中也一样。但是我们要分类讨论一下:如果 rear > front 且队列未满,很显然和普通队列一样,长度为 rear - front ;但如果 rear < front ,队列的长度是一圈中两者之间夹的部分,而它们的距离是 front - rear 。所以这时的长度就是一整圈再减去之间的距离,也就是 max - ( front - rear ) ,去括号可得长度为 rear - front + max。而这两种情况,再进行合并,就会得到长度 = (rear - front + max)% max 。为什么呢?我们设 x = rear - front ( t<=max )。当 rear > front 时,x 显然为正数。那么 max 加上一个比它小的数,根本就没有影响它的倍数(还是一倍),故此时 (max + x) % max 商一余 x ,即 rear - front;当 rear < front 时,x 为负数。 我们另 t = -x (t>=0)。那么 max 减去一个比它小的数,倍数就变了(变小了)。此时(max -t)% max 商零余 max - t,也就是 max - [-(rear - front) ],即 rear - front + max。
综上,求循环队列的长度:
return (rear - front + max)% max ⑤取首元素:
与普通相同,但要取模:
return q[(front + 1) % max]; 6.总结:
先进先出,后进后出。
判满入队,判空出队。
求好长度,取首元素。
循环队列,千万别忙。
判满取模,判空照常。
分类讨论,二合为一。
尾首相减,加后取模。
typedef struct { uint32_t *buf; uint32_t cap; uint32_t head; uint32_t tail; } ring_queue; 结构体里保存了所用内存的指针、容量,保存了队头和队尾。
uint32_t rq_len(ring_queue *rq) { return rq->tail - rq->head; } 队列长度直接就是 tail - head。
void rq_push(ring_queue *rq, uint32_t value) { if rq_len() == cap { error(); } rq->buf[rq->tail % rq->cap] = value; rq->tail += 1; } 入队时首先对 tail 取模,模数为 cap,得到真实索引,然后把值写入队列空间,最后把 tail 加 1。
uint32_t rq_pop(ring_queue *rq) { if rq_len() == 0 { error(); } uint32_t value = rq->buf[rq->head % rq->cap]; rq->head += 1; return value; } 出队时首先对 head 取模,模数为 cap,得到真实索引,然后读取队列元素,最后把 head 加 1。
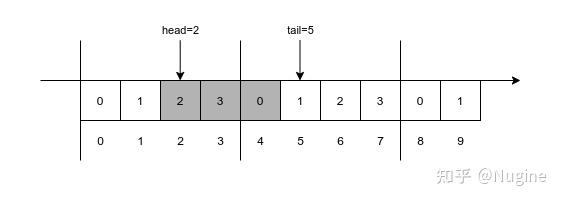
如图所示,cap = 4,head = 2,tail = 5。
循环队列的空间可以认为是一条无限长的数轴,head 和 tail 是上面的数字。
[head, tail) 是左闭右开的区间,区间长度是队列长度,其中的数字代表队列元素。图中的区间 [2, 5) 中有 2,3,4 三个数字,也就代表队列元素有 3 个。
对数字取模可以得到队列元素在队列空间中的位置,2,3,4 对应的位置是 2,3,0。
无限次入队出队后,head 和 tail 会非常大,有可能溢出 uint32_t 类型的最大值。但队列在这种情况下仍然能正常工作。tail - head 会自然溢出,相当于取模 M,其中 M 为 。只要保证队列长度小于 M,
tail - head 得到的就是真正的队列长度。
当 cap 为 2 的幂时,有 x % cap == x & (cap - 1),可以用位运算取代消耗较大的模运算。
相比常见的实现,这种写法不需要额外记录队列长度,也不需要浪费一个元素的空间,还能轻易改造成无锁循环队列。这也是 Linux 内核中 kfifo 结构所使用的写法。
顺序队列
循环队列
队列(Queue)与栈都是线性存储结构,因此以常见的线性表如数组、链表作为底层的数据结构,特点:
- 先进先出(First In First Out)的原则,简称FIFO结构
- 队尾添加元素,队首删除元素
相关概念:
- 队头与队尾: 允许元素插入的一端称为队尾,允许元素删除的一端称为队头
- 入队:队列的插入操作
- 出队:队列的删除操作
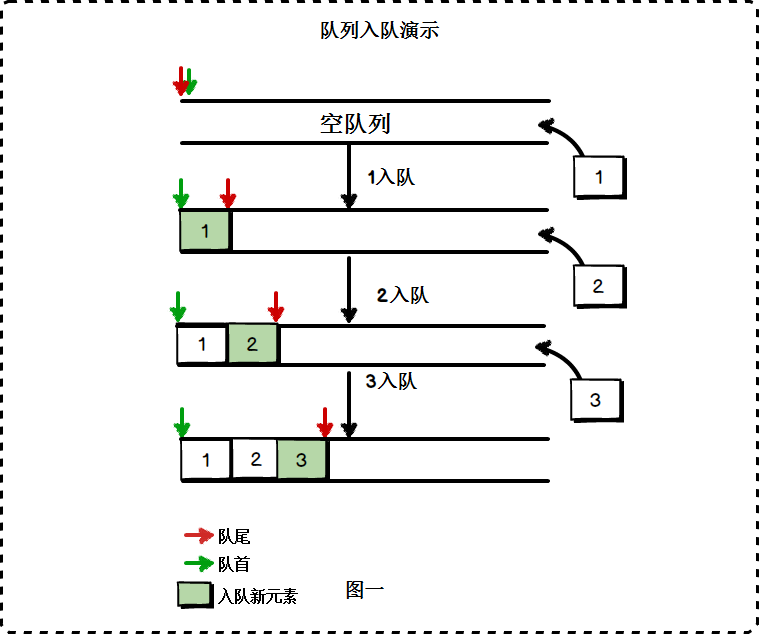
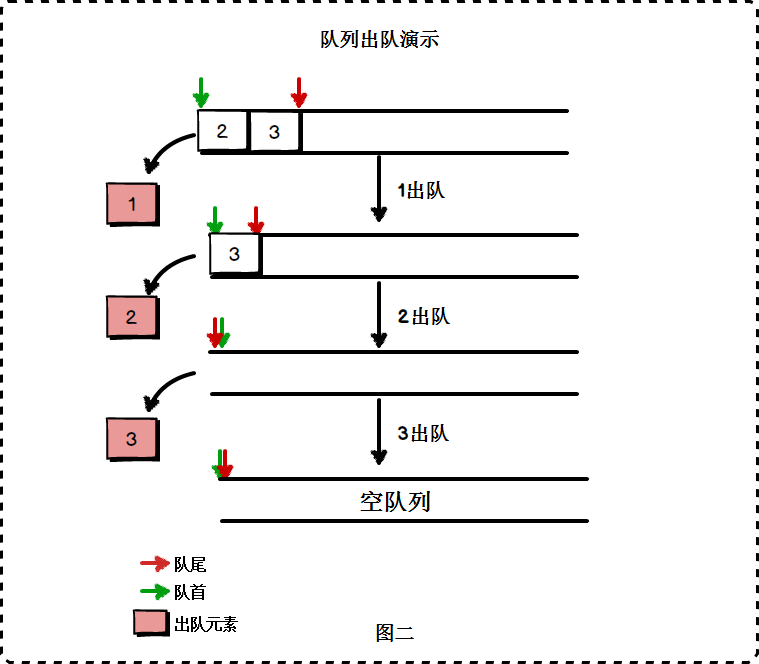
顺序存储上的不足:每次从数组头部删除元素(出队)后,需要将头部以后的所有元素往前移动一个位置,这是一个时间复杂度为O(n)的操作:
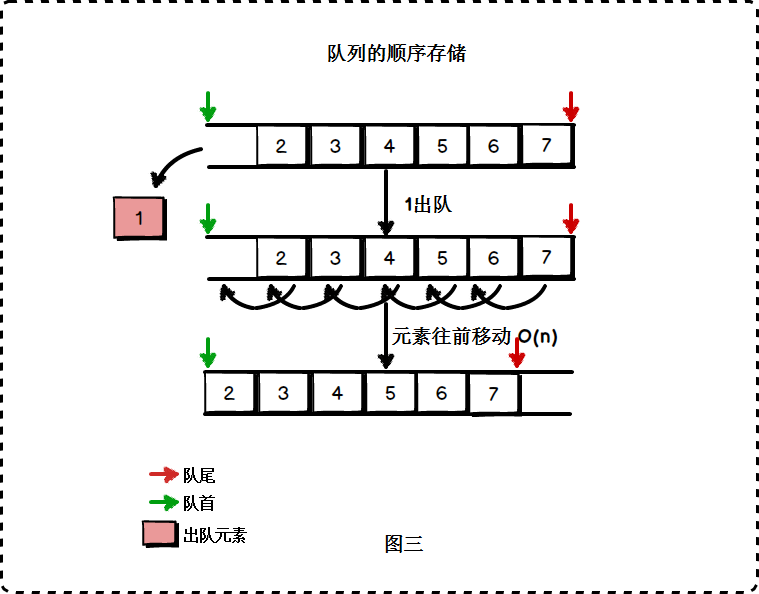
可能有人说,把队首标志往后移动不就不用移动元素了吗?但那样会造成数组空间的“流失”。我们希望队列的插入与删除操作都是O(1)的时间复杂度,同时不会造成数组空间的浪费,我们应该使用循环队列。
package main import ( "errors" "fmt" "os" ) // 使用结构体管理队列 type Queue struct { Maxsize int array [5]int //数组 模拟队列 front int // 指向队列首部 real int // 指向队列 尾部 } // 入队 func (this *Queue) Push(val int) (err error) { // 判断队列是否满 if this.real == this.Maxsize-1 { return errors.New("queue full") } this.real++ this.array[this.real] = val return } // 显示队列 func (this *Queue) showQueue() { for i := this.front + 1; i <= this.real; i++ { fmt.Printf("%d\t", this.array[i]) } fmt.Println() } // 出队 func (this *Queue) Pop() (val int, err error) { if this.front == this.real { return val, errors.New("queue empty") } this.front++ val = this.array[this.front] return } func main() { queue := &Queue{ Maxsize: 5, front: -1, real: -1, } var key string var val int for { fmt.Printf("1、输入push 入队\n2、输入pop 出队\n3、输入show 显示队列\n4、输入eixt 表示退出\n") fmt.Scanln(&key) switch key { case "push": fmt.Println("请输入你要入队的数据:") fmt.Scanln(&val) err := queue.Push(val) if err != nil { fmt.Println(err) } else { fmt.Println("入队成功") } case "pop": val, err := queue.Pop() if err != nil { fmt.Println(err) } else { fmt.Println("出队数值",val) } case "show": queue.showQueue() case "exit": os.Exit(-1) } } } 它可以把数组看出一个首尾相连的圆环,删除元素时将队首标志往后移动,添加元素时若数组尾部已经没有空间,则考虑数组头部的空间是否空闲,如果是,则在数组头部进行插入。
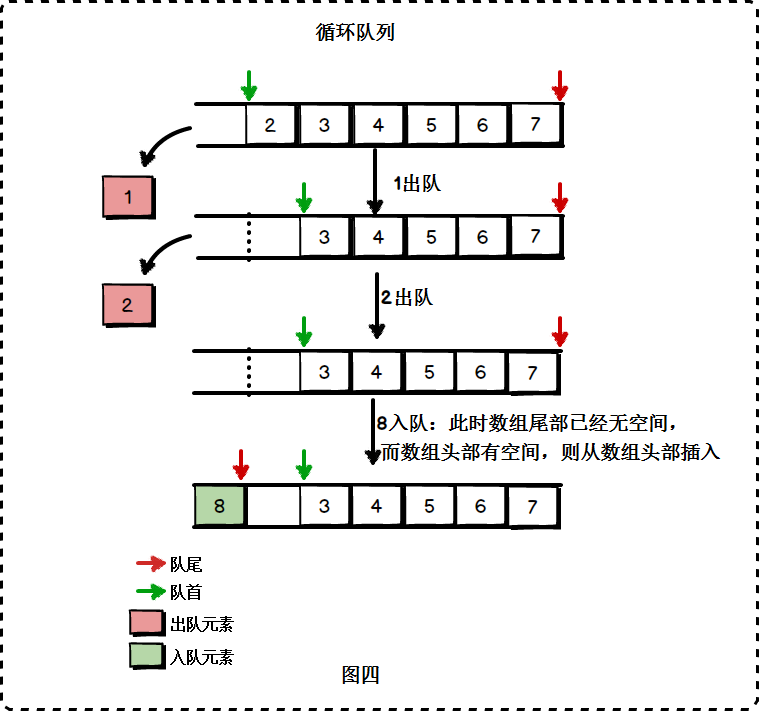
循坏队列的核心在队头指针和队尾指针的增加方式:
this.tail=(this.tail+1)%this.maxsize this.head=(this.head+1)%this. 当队列为空时this.head = this.tail,当队列为满时也有this.head = this.tail造成了判断队列是空还是满的二义性
解决方法:
1.增加一个参数,使删除元素为1,插入元素为0
2.增加一个参数,记录队列的元素个数即长度
3.空出一个单元,令(this.tail+1)%this.maxsize == this.head为队列为满的条件,以此解决二义性
基于数组实现循坏队列 代码
package main import ( "errors" "fmt" "os" ) // 使用结构体管理队列 type CycleQueue struct { maxsize int array [5]int //数组 head int //队首 tail int //队尾 } // 入队列 func (this *CycleQueue) Push(val int) error { if this.IsFull() { return errors.New("queue full") } this.array[this.tail] = val this.tail=(this.tail+1)%this.maxsize return nil } //出队列 func (this *CycleQueue) Pop() (val int, err error) { if this.IsEmpty() { return val, errors.New("queue empty") } val = this.array[this.head] this.head=(this.head+1)%this.maxsize return val, nil } //显示队列 func (this *CycleQueue) ShowQ() { size := this.Size() if size == 0 { fmt.Println("queue is empty") } //辅助变量 指向head tempHead := this.head for i := 0; i < size; i++ { fmt.Println(this.array[tempHead]) tempHead = (tempHead + 1) % this.maxsize } } //判断循环队列是否为空 func (this *CycleQueue) IsEmpty() bool { return this.tail == this.head } //判断循环队列是否满 func (this *CycleQueue) IsFull() bool { return (this.tail+1)%this.maxsize == this.head } //统计队列元素 个数 func (this *CycleQueue) Size() int { return (this.tail + this.maxsize - this.head) % this.maxsize } func main() { queue := &CycleQueue{ maxsize: 5, tail: 0, head: 0, } var key string var val int for { fmt.Printf("1、输入push 入队\n2、输入pop 出队\n3、输入show 显示队列\n4、输入eixt 表示退出\n") fmt.Scanln(&key) switch key { case "push": fmt.Println("请输入你要入队的数据:") fmt.Scanln(&val) err := queue.Push(val) if err != nil { fmt.Println(err) } else { fmt.Println("入队成功") } case "pop": val, err := queue.Pop() if err != nil { fmt.Println(err) } else { fmt.Println("出队数值", val) } case "show": queue.ShowQ() case "exit": os.Exit(-1) } } } 以下是《懒猫老师-数据结构-(10)队列(循环队列)》课程的PPT文档,请点击以下链接观看懒猫老师的教学视频。
懒猫老师-数据结构-(10)队列(循环队列)_哔哩哔哩 (゜-゜)つロ 干杯~-bilibili
《跟懒猫老师快乐学数据结构》汇总目录见以下链接:
懒猫老师:《跟懒猫老师快乐学数据结构》目录





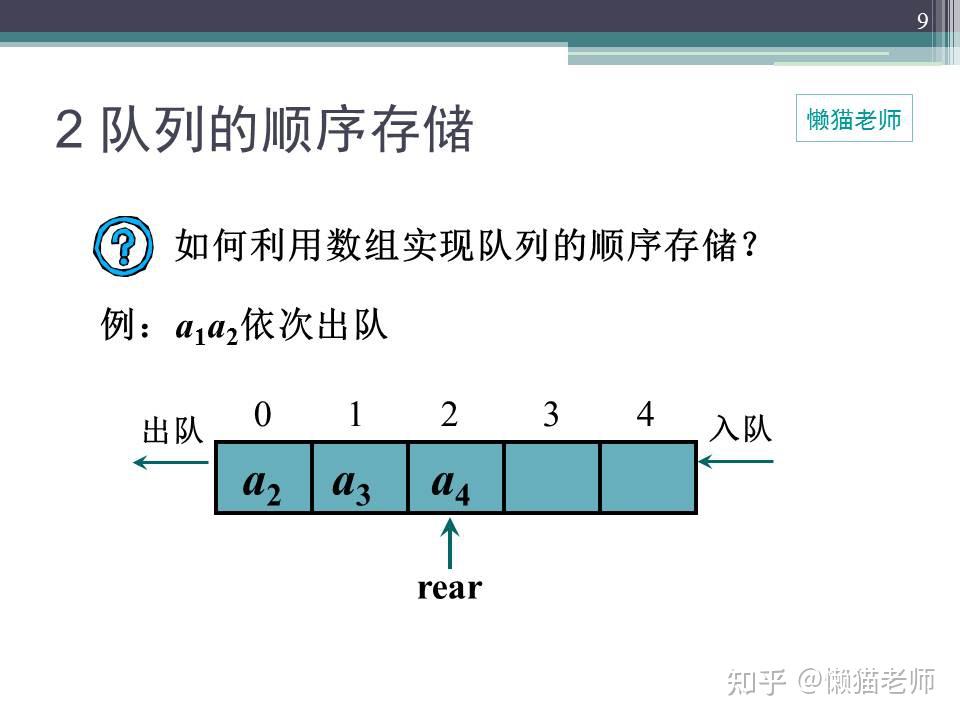
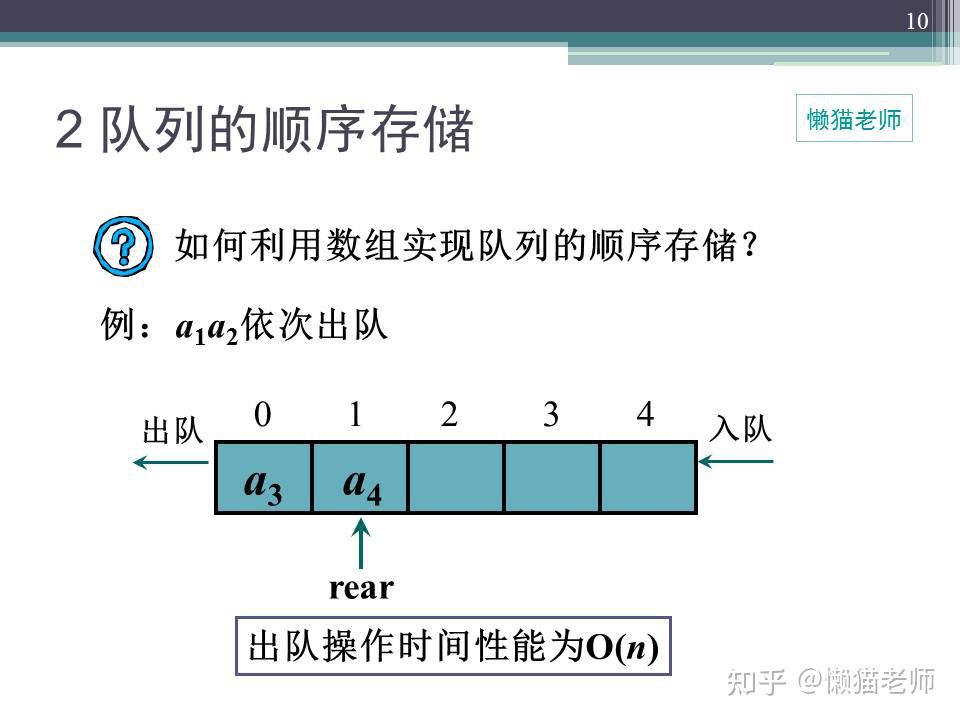



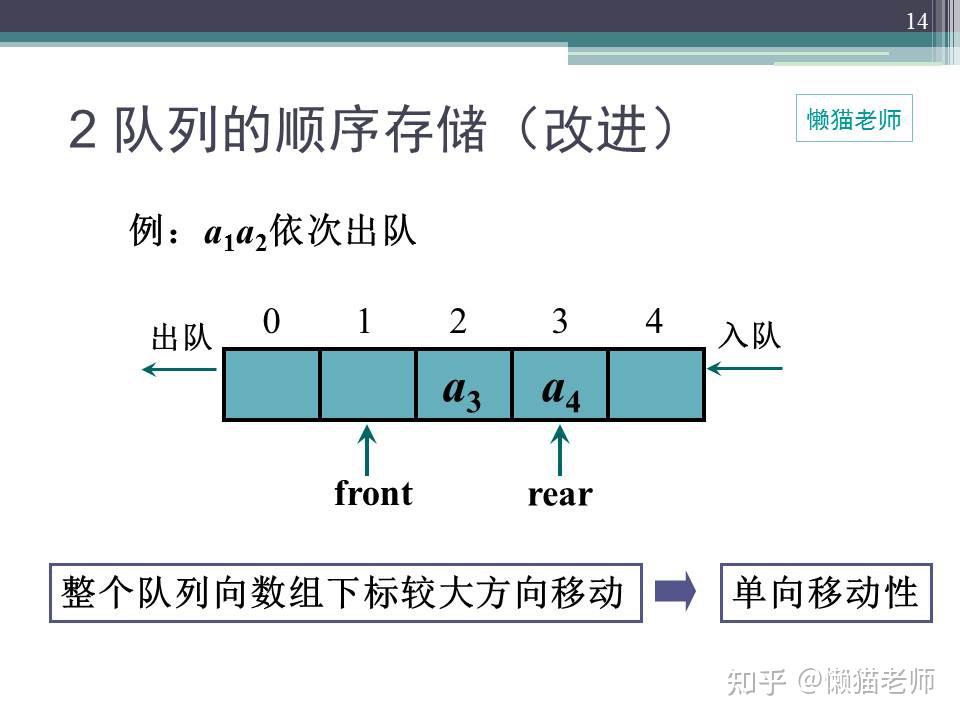

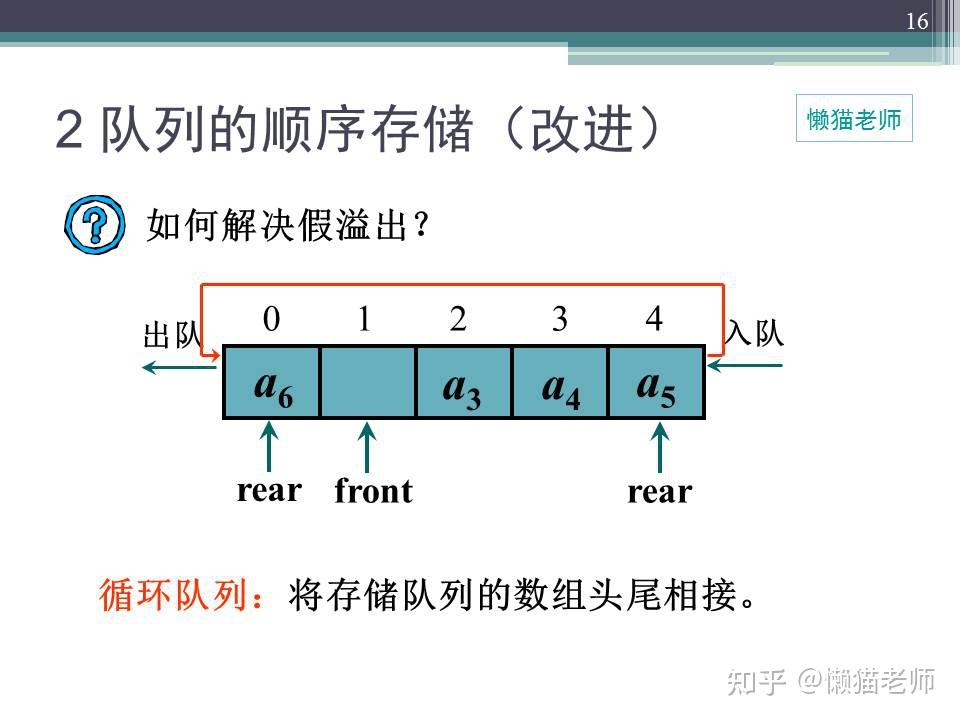

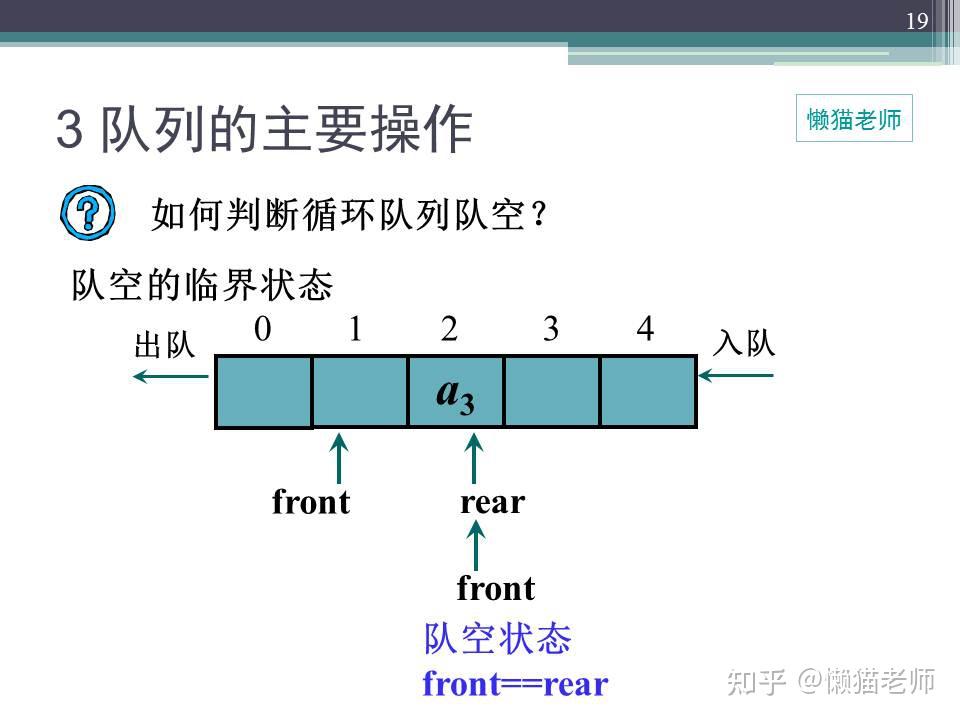













当代码,不再是简单的完成需求,对代码进行堆砌,而是开始思考如何写出优美代码的时候,我们的代码水平必然会不断提升,今天,咱们来学习环形队列结构。
相信对数据结构有过接触的小伙伴,对队列肯定不会陌生,队列相对来说是比较简单的数据结构,典型特点是FIFO,即First in First out,先进先出,就像我们日常排队买票一样,先到的人先买票,先从购票口出去,从下面的图中,可以比较形象的了解队列的特性。

用数组创建一个普通队列,当有数据存储时,队列尾指针不断增加,直到空间用完,当数据出队列时,队列头指针不断增加,直至和队列尾相同时,所有数据完成出队列,那么这时候会引入一个问题,全部出队后,将无法继续入队,这样的情况也叫做“假溢出”,即使数组中,明明还有空间可以利用,但是却无法使用(平时我们做串口接收的时候,往往是通过清零计数器,清空数组,重新接收来解决这一问题)。
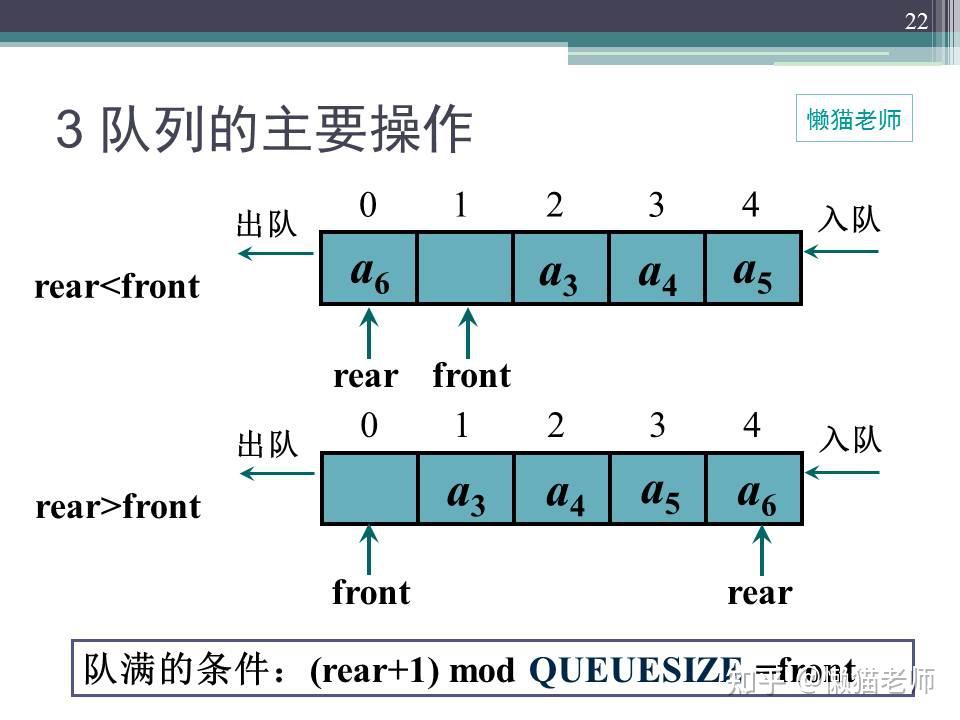
只要思想不滑坡,方法总比困难多。为了解决上面“假溢出”的现象,环形队列应运而生,即通常将一维数组Queue[0]到Queue[MAXSIZE - 1]看成是一个首尾相连接的圆环,即Queue[0]与Queue[MAXSIZE - 1]相连接在一起,将这样形式的队列成为循环队列。
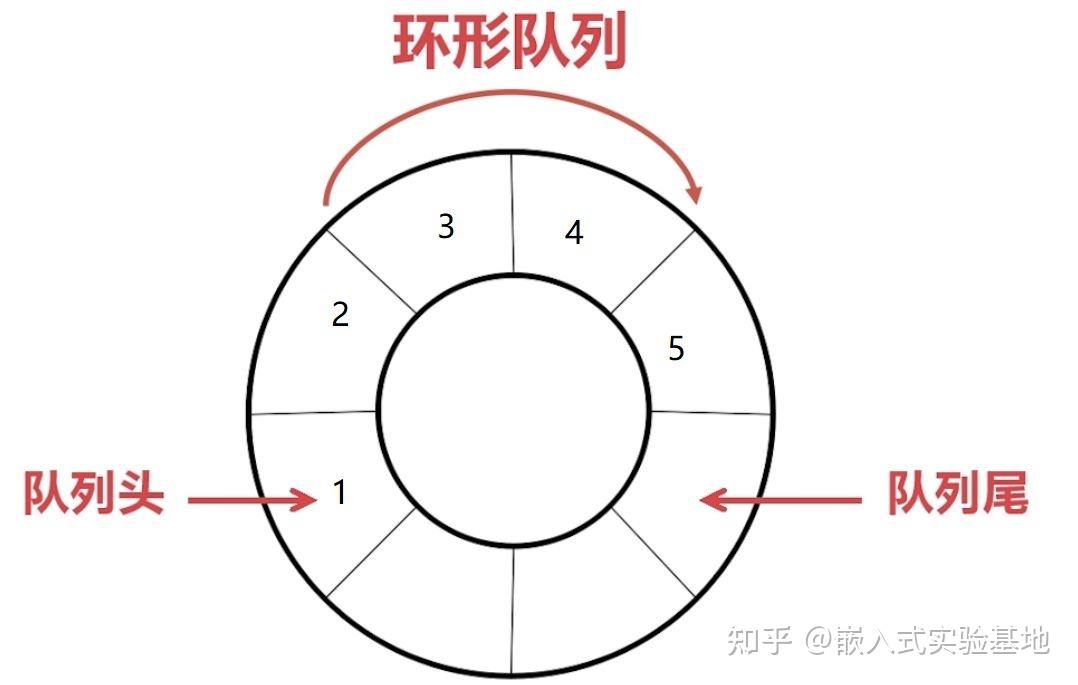
在计算机的内存中,是不存在所谓的环形内存区域的,所以,需要程序员认为的“画个圈圈”,从图示环形队列来看,存储空间有限,当数据存到末端时,如何处理呢,只需要重新转回0的地址区域,有点像“驴拉磨”的意思......
环列队列的是逻辑上将数组元素q[0]与q[MAXN-1]连接,形成一个存放队列的环形空间。
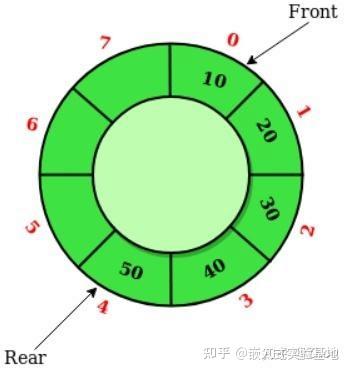
环形队列设计的重要部分是,确定队列的状态,即队列时空还是满状态。根据上面介绍的存储顺序,数据存储时,队列尾指针移动,头指针不动,数据读取时,头指针移动,尾指针不动,但是如果从单纯的“tail==head”还无法得出是处于空还是满状态,需要加些判断手段:
- 附件标志法
1、tail追上head时,tag=1,队列为满状态
2、head追上tail时,tag=0,队列为空状态
- 预留位置法
在存储数据时,最后一个位置与队列头预留至少一个单位的空间
1、head==tail 队列为空
2、(tail+1)% MAXN ==head 队列满
环形队列的原理也算比较简单,弄清楚了原理之后,进行代码的编写。
- 方法1:附加标志法
先来定义个结构体:
typedef struct Squeue { /*顺序循环队列的类型定义*/ DataType queue[QUEUESIZE]; int front, rear; /*队头指针和队尾指针*/ int tag; /*队列空、满的标志*/ } SCQueue; 初始化队列:
/*将顺序循环队列初始化为空队列,需要把队头指针和队尾指针同时置为0,且标志位置为0*/ void InitQueue(SCQueue *SCQ) { SCQ->front = SCQ->rear = 0; /*队头指针和队尾指针都置为0*/ SCQ->tag = 0; /*标志位置为0*/ } 判断是否为空队列:
/*判断顺序循环队列是否为空,队列为空返回1,否则返回0*/ int QueueEmpty(SCQueue SCQ) { if (SCQ.front == SCQ.rear && SCQ.tag == 0) /*队头指针和队尾指针都为0且标志位为0表示队列已空*/ return 1; else return 0; } 插入元素:
/*将元素e插入到顺序循环队列SQ中,插入成功返回1,否则返回0*/ int EnQueue(SCQueue *SCQ, DataType e) { if (SCQ->front == SCQ->rear && SCQ->tag == 1) /*在插入新的元素之前,判断是否队尾指针到达数组的最大值,即是否上溢*/ { printf("顺序循环队列已满,不能入队!"); return 1; } else { SCQ->queue[SCQ->rear] = e; /*在队尾插入元素e */ SCQ->rear = (SCQ->rear + 1) % QUEUESIZE; //SCQ->rear = SCQ->rear + 1; /*队尾指针向后移动一个位置,指向新的队尾*/ } if (SCQ->rear == SCQ->front) { SCQ->tag = 1; /*队列已满,标志位置为1 */ } return SCQ->tag; } 读取元素:
/*删除顺序循环队列中的队头元素,并将该元素赋值给e,删除成功返回1,否则返回0*/ int DeQueue(SCQueue *SCQ, DataType *e) { if (QueueEmpty(*SCQ)) /*在删除元素之前,判断队列是否为空*/ { printf("顺序循环队列已经是空队列,不能再进行出队列操作!"); return 0; } else { *e = SCQ->queue[SCQ->front]; /*要出队列的元素值赋值给e */ SCQ->front = (SCQ->front + 1) % QUEUESIZE; /*队头指针向后移动一个位置,指向新的队头元素*/ SCQ->tag = 0; /*删除成功,标志位置为0 */ } if (SCQ->rear == SCQ->front) { SCQ->tag = 0; /*队列已空,标志位置为0 */ } return SCQ->tag; } 先来对这种方法进行测试:
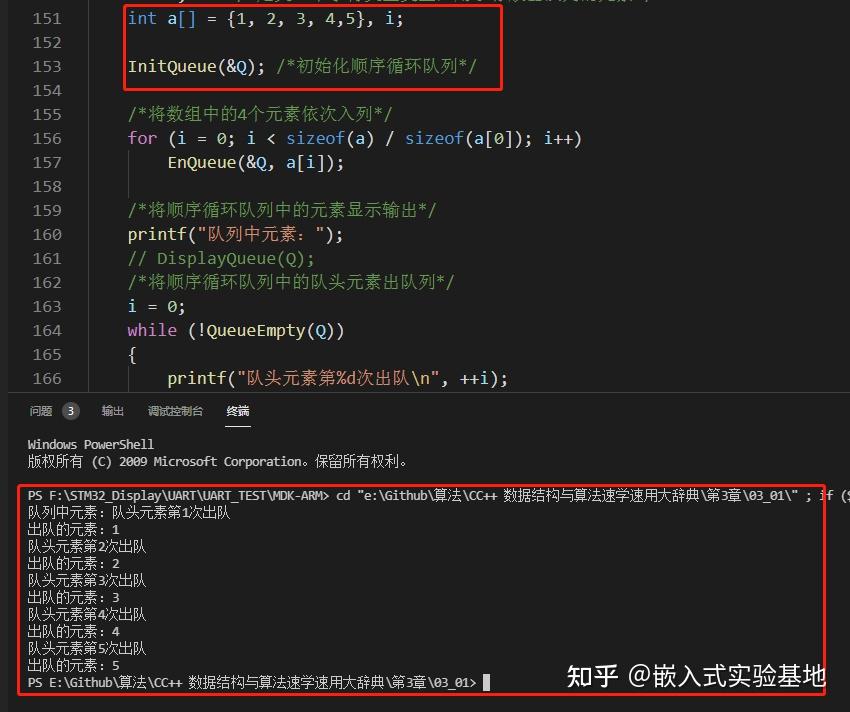
void main() { SCQueue Q; /*定义一个顺序循环队列*/ int e; /*定义一个字符类型变量,用于存放出队列的元素*/ int a[] = {1, 2, 3, 4,5}, i; InitQueue(&Q); /*初始化顺序循环队列*/ /*将数组中的4个元素依次入列*/ for (i = 0; i < sizeof(a) / sizeof(a[0]); i++) EnQueue(&Q, a[i]); /*将顺序循环队列中的元素显示输出*/ printf("队列中元素:"); // DisplayQueue(Q); /*将顺序循环队列中的队头元素出队列*/ i = 0; while (!QueueEmpty(Q)) { printf("队头元素第%d次出队\n", ++i); DeQueue(&Q, &e); printf("出队的元素:"); printf("%d\n",e); // PrintData(e); } } 测试结果:
- 预留位置法
代码与第一种方法区别不大,主要在空、满状态的判断上,代码如下:
/*将顺序循环队列初始化为空队列,需要把队头指针和队尾指针同时置为0,且标志位置为0*/ void InitQueue(SCQueue *SCQ) { SCQ->front = SCQ->rear = 0; /*队头指针和队尾指针都置为0*/ SCQ->tag = 0; /*标志位置为0*/ } //获取队列长度 int QueueLength(SCQueue *SCQ) { return (SCQ->rear - SCQ->front + QUEUESIZE) % QUEUESIZE; } /*判断顺序循环队列是否为空,队列为空返回1,否则返回0*/ int QueueEmpty(SCQueue SCQ) { if (SCQ.front == SCQ.rear) /*队头指针和队尾指针都为0且标志位为0表示队列已空*/ return 1; else return 0; } /*将元素e插入到顺序循环队列SQ中,插入成功返回1,否则返回0*/ int EnQueue(SCQueue *SCQ, DataType e) { /*在插入新的元素之前,判断是否队尾指针到达数组的最大值,即是否上溢*/ if ((SCQ->rear + 1) % QUEUESIZE == SCQ->front) { printf("顺序循环队列已满,不能入队!"); return 0; } SCQ->queue[SCQ->rear] = e; /*在队尾插入元素e */ SCQ->rear = (SCQ->rear + 1) % QUEUESIZE; /*队尾指针向后移动一个位置,指向新的队尾*/ printf("数据已插入"); } /*删除顺序循环队列中的队头元素,并将该元素赋值给e,删除成功返回1,否则返回0*/ int DeQueue(SCQueue *SCQ, DataType *e) { if (QueueEmpty(*SCQ)) /*在删除元素之前,判断队列是否为空*/ { printf("顺序循环队列已经是空队列,不能再进行出队列操作!"); return 0; } else { *e = SCQ->queue[SCQ->front]; /*要出队列的元素值赋值给e */ SCQ->front = (SCQ->front + 1) % QUEUESIZE; /*队头指针向后移动一个位置,指向新的队头元素*/ return 1; } } main函数与上面相同:
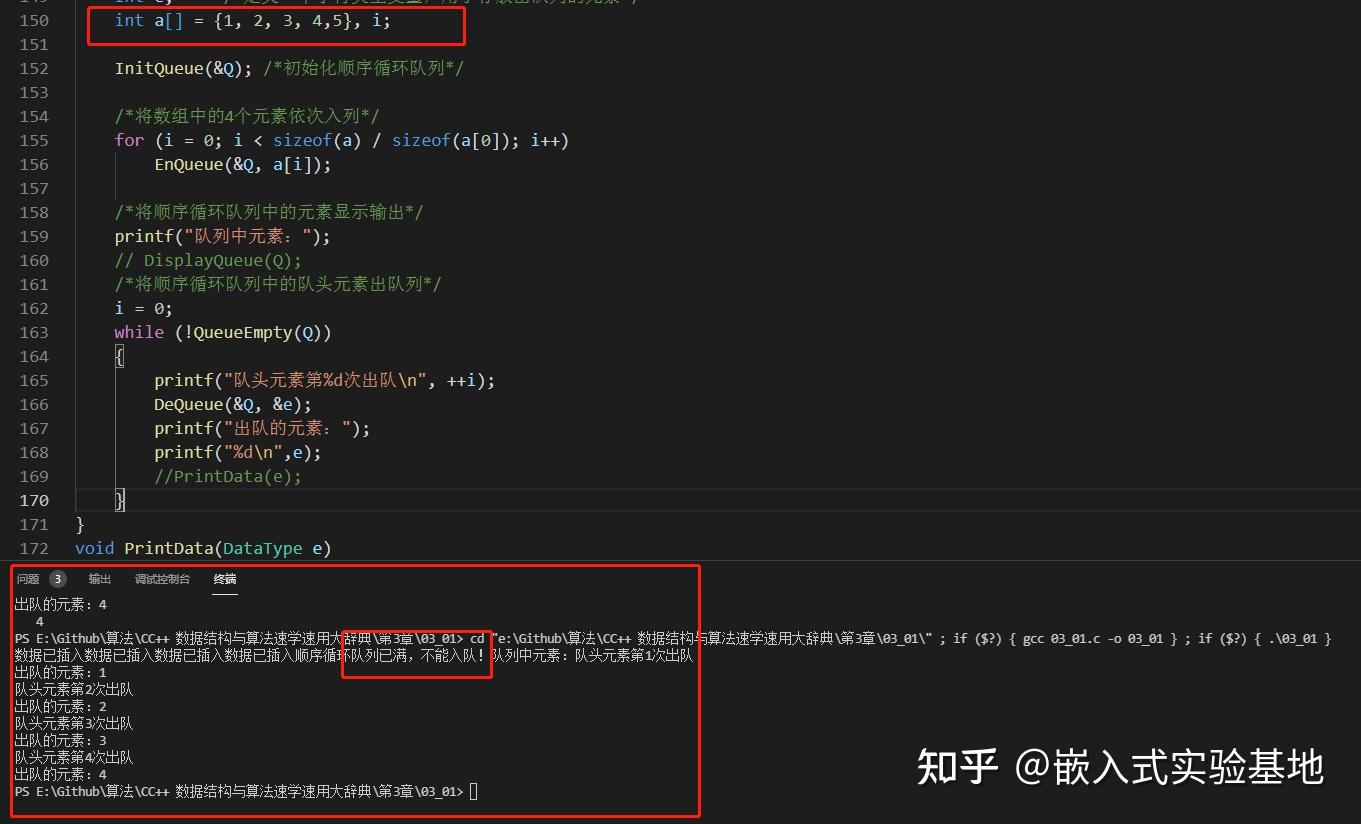
void main() { SCQueue Q; /*定义一个顺序循环队列*/ int e; /*定义一个字符类型变量,用于存放出队列的元素*/ int a[] = {1, 2, 3, 4,5}, i; InitQueue(&Q); /*初始化顺序循环队列*/ /*将数组中的4个元素依次入列*/ for (i = 0; i < sizeof(a) / sizeof(a[0]); i++) EnQueue(&Q, a[i]); /*将顺序循环队列中的元素显示输出*/ printf("队列中元素:"); // DisplayQueue(Q); /*将顺序循环队列中的队头元素出队列*/ i = 0; while (!QueueEmpty(Q)) { printf("队头元素第%d次出队\n", ++i); DeQueue(&Q, &e); printf("出队的元素:"); printf("%d\n",e); //PrintData(e); } } 测试结果:
相比较上面的测试结果,小伙伴们有没有发现什么不同之处呢,我们main函数想把5个元素写入队列,实际上只写进去了4个,原因在与,我们预留了一个单元空间,用于判断队列空或者满的状态。
本次的介绍就到这里啦,下章介绍:环形队列在单片机中的应用,欢迎大家持续关注嵌入式实验基地,来这里还可以学习HAL库+cubemx的更多精彩内容哦!

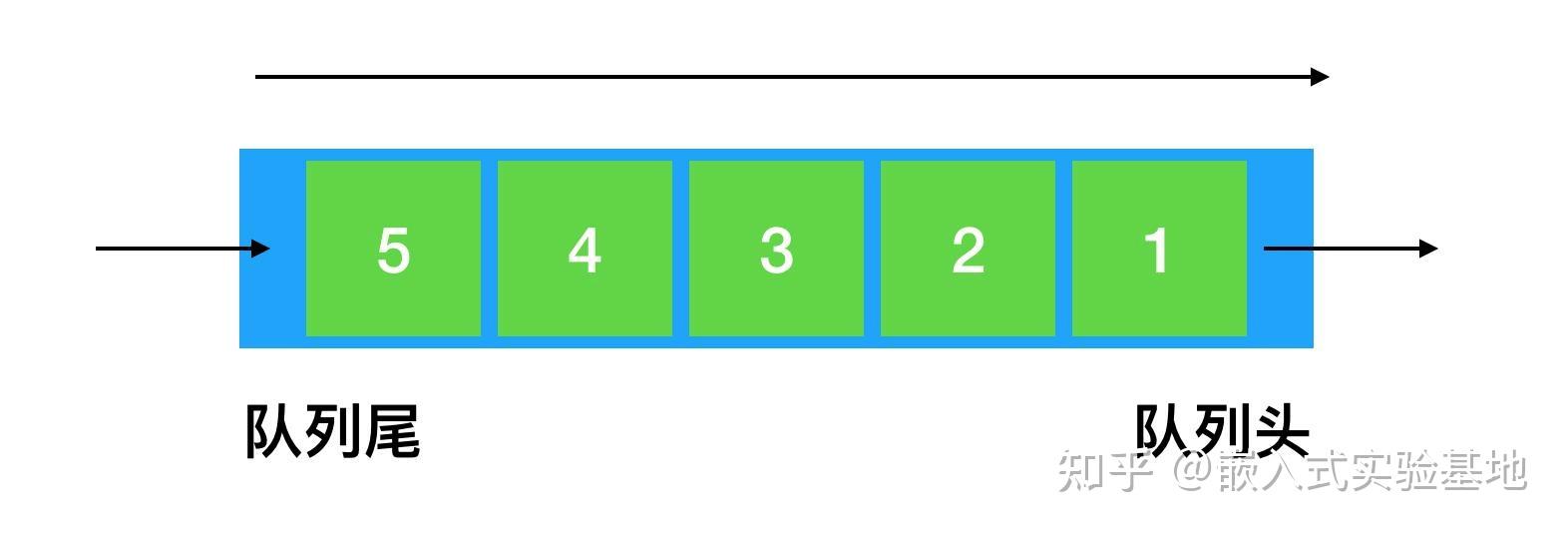
队列是一种先进先出的线性表,简称FIFO。允许插入的一端称为队尾,允许删除的一端称为队头,如下图所示。
普通的顺序队列我们设置队头指针(front)和队尾指针(rear)来描述队列里的数据存储位置。初始两个指针都指向0号元素,如下图所示。
当入队时,rear指针向尾部移动,front指针则依旧指向首元素,如下图所示。
当出队时,front指针向下一个元素移动,释放出队元素,尾指针不变,入下图所示。
当出队入队次数足够多时,我们会发现队列不能入队了,但是却还有空间,如下图所示。
这就是所谓的队列“假溢出”现象,所造成得空间浪费,所以我们需要使用循环队列来解决。所谓循环队列,就是将队列的头尾相接,这样就不会出现上述问题。
但是由于rear指针相当于头指针,是不指向元素的,所以我们实际的元素数量要比队列空间少一个,如下图所示,队列总长度为6,实际元素个数为5个,还有一个被rear指针使用。
以上转自:
卡卡:六、循环队列
实战:(C++模板类实现循环队列)
1)创建基类
#ifndef QUEUEBASE_H #define QUEUEBASE_H template<typename T> class QueueBase{ public: QueueBase(){} ~QueueBase(){} virtual bool enque(const T&)=0; virtual bool deque(T&)=0; virtual bool front(T&)=0; virtual bool rear(T&)=0; virtual bool is_empty()const=0; virtual bool is_full()const=0; virtual int size() =0; virtual int maxSzie()=0; }; #endif // QUEUEBASE_H 2)派生类
#ifndef CUSTOMMSGCIRCLEQUEUE_H #define CUSTOMMSGCIRCLEQUEUE_H #include <iostream> #include <stdlib.h> #include "QueueBase.h" /* 约定牺牲存储空间中的一个存储单元来定义入队和出队条件 出队时,当rear==front队空,不能出队; 入队时,当(rear+1)%MAXSIZE==front队满,不能入队。 */ template <typename T> class CustomMsgCircleQueue : public QueueBase<T> { public: //默认构造函数 CustomMsgCircleQueue(); //自定义构造函数 CustomMsgCircleQueue(size_t); //析构函数 ~CustomMsgCircleQueue(); //出队操作 virtual bool deque(T&); //入队操作 virtual bool enque(const T&); //查看队列首端元素 virtual bool front(T&); //查看队列末端元素 virtual bool rear(T&); //队列是否非空 virtual bool is_empty() const; //队列是否已满 virtual bool is_full() const; //返回队列已有数量 virtual int size(); //返回队列maxsize virtual int maxSzie(); //缓存 const T *buffer(); private: //内部元素队列指针 int d_rear; int d_front; int d_size; int d_maxsize; T *d_arr; }; ////////////////////////////////////定义/////////////////////////////////// /*模板类申明和定义放在.h文件中 否则定义该派生模板类对象时,会报错:构造和析构函数未定义 */ #define DEFAULT_SIZE 200 template <typename T> CustomMsgCircleQueue<T>::CustomMsgCircleQueue() { d_front = -1; d_rear = -1; d_maxsize = DEFAULT_SIZE; d_size = 0; d_arr = new T[d_maxsize]; } //构造函数 template <typename T> CustomMsgCircleQueue<T>::CustomMsgCircleQueue(size_t size) { d_size = 0; d_maxsize = size; d_front = -1; d_rear = -1; d_arr = new T[d_maxsize]; } //析构函数 template <typename T> CustomMsgCircleQueue<T>::~CustomMsgCircleQueue() { delete[] d_arr; //d_arr = nullptr; } //检查环形队列是否为满载 template <typename T> bool CustomMsgCircleQueue<T>::is_full() const { return d_front == (d_rear + 1) % d_maxsize; } //返回队列已有数量 template <typename T> int CustomMsgCircleQueue<T>::size() { return d_size; } //判断环形队列是否为空 template <typename T> bool CustomMsgCircleQueue<T>::is_empty() const { return d_front == d_rear; } //入队操作 template <typename T> bool CustomMsgCircleQueue<T>::enque(const T &value) { if (is_full()) { std::cout << "环形队列已满" << std::endl; return false; } else if (d_front == -1) { d_rear = d_front = 0; } else if (d_rear == d_maxsize - 1 && d_front != 0) { d_rear = 0; } else { d_rear++; } d_arr[d_rear] = value; d_size++; return true; } //出队操作 template <typename T> bool CustomMsgCircleQueue<T>::deque(T & value) { if (is_empty()) { std::cout << "环形队列为空" << std::endl; return false; } value = d_arr[d_front]; if (d_front == d_rear) { d_front = -1; d_rear = -1; } else if (d_front == d_size - 1) { d_front = 0; } else { d_front++; } d_size--; return true; } //获取队头部元素 template <typename T> bool CustomMsgCircleQueue<T>::front(T& value) { if (is_empty()) { std::cout << "环形队列为空" << std::endl; return false; } value = d_arr[d_front]; return true; } //获取队尾元素 template <typename T> bool CustomMsgCircleQueue<T>::rear(T& value) { if (is_empty()) { std::cout << "环形队列为空" << std::endl; return false; } value = d_arr[d_rear]; return true; } //获取队列尺寸 template <typename T> int CustomMsgCircleQueue<T>::maxSzie() { return d_maxsize; } //获取队列内部的缓存指针 template <typename T> const T *CustomMsgCircleQueue<T>::buffer() { return d_arr; } #endif // CUSTOMMSGCIRCLEQUEUE_H 3)派生模板类对象创建
在消息接受线程中
CustomMsgCircleQueue<char*>gCirclequeue; char msg[MAXBUFSIZE]; .......//拷贝数据到msg gCirclequeue.enque(msg);//数据入环形队列 在消息解析线程中
char* msg2; while(true) { if(gCirclequeue.deque(msg2)) { qDebug()<<"msg2 message is "<<msg2; } ..... } 4)实际测试 通过~
现在假设数据只进入队列,而不出队列,即front=0,在原处,而rear在不断增加。
此时显然,循环队列的元素个数为rear-front=rear-0 =rear, 如下图
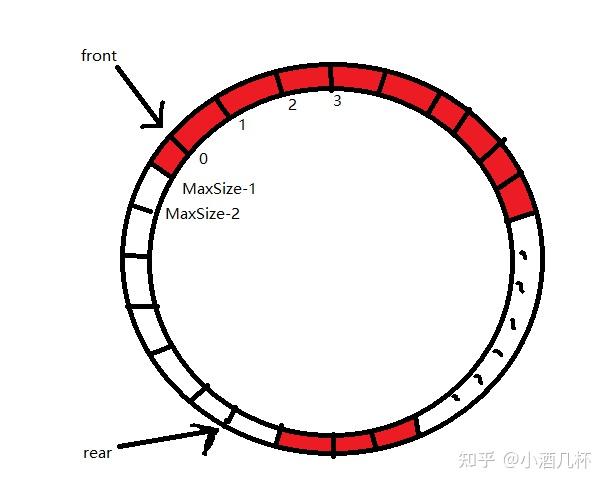
假设数据进入队列,有出队列,如下图
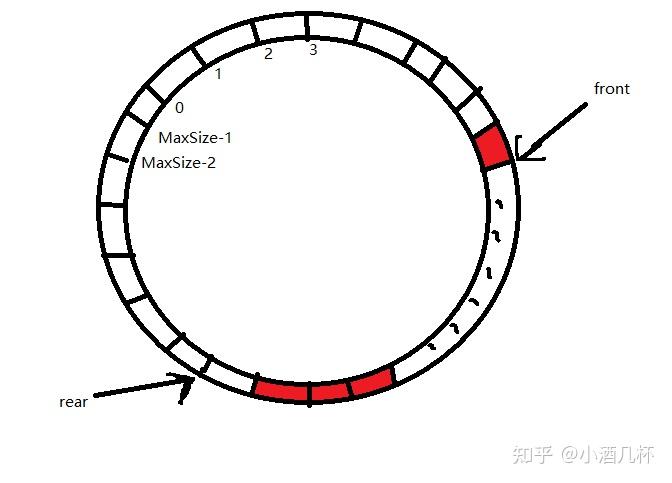
由上面可知,如果,数据只进入队列,而不出队列,则队列元素为rear,
那得到一个思路,就是旋转循环队列,让front=0,回到原处,rear不就是元素个数了吗
那就用顺时针旋转环 ,设 front=MaxSize-x,
显然 ,当front移动x个单位时,front=(MaxSize-x+x)%MaxSize =0
front回到了原处
同rear也要移动x个位置, =(rear+x)%MaxSize
x=MaxSize-front
所以,循环队列的元素个数即为 (rear+MaxSize-front)%MaxSize
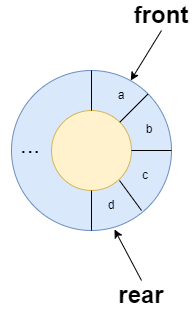
为充分利用向量空间,克服"假溢出"现象的方法是:将向量空间想象为一个首尾相接的圆环,并称这种向量为循环向量。存储在其中的队列称为循环队列(Circular Queue)。循环队列是把顺序队列首尾相连,把存储队列元素的表从逻辑上看成一个环,成为循环队列。
在循环队列结构中,设置一个队尾 rearrear 与队首 frontfront,且大小固定,结构如下图所示[1]:


如上文所介绍, 大概有两种方法实现。一是如上文缩写,不用cnt, 只用front和rear计算位置
class MyCircularQueue { private: int front; int rear; int capacity; vector<int> elements; public: MyCircularQueue(int k): capacity(k+1), elements(vector<int>(capacity)), front(0), rear(0) {} bool enQueue(int value) { if (isFull()) return false; elements[rear] = value; rear = (rear + 1) % capacity; return true; } bool deQueue() { if (isEmpty()) { return false; } front = (front + 1) % capacity; return true; } int Front() { if (isEmpty()) { return -1; } return elements[front]; } int Rear() { if (isEmpty()) { return -1; } return elements[(rear - 1 + capacity) % capacity]; } bool isEmpty() { return rear == front; } bool isFull() { return ((rear + 1) % capacity) == front; } }; 也可以朴素一些,用cnt计算目前的总元素个数, 同时省略rear , 因为可以动态计算出来
class MyCircularQueue { public: / Initialize your data structure here. Set the size of the queue to be k. */ MyCircularQueue(int k):capacity(k), queue(vector<int> (k,0)), cnt(0), head(0){ } / Insert an element into the circular queue. Return true if the operation is successful. */ bool enQueue(int value) { if(cnt==capacity) return false; queue[(head+cnt)%capacity]=value; cnt++; return true; } / Delete an element from the circular queue. Return true if the operation is successful. */ bool deQueue() { if(cnt==0) return false; head=(head+1)%capacity; cnt--; return true; } / Get the front item from the queue. */ int Front() { if(cnt==0) return -1; return queue[head]; } / Get the last item from the queue. */ int Rear() { if(cnt==0) return -1; return queue[(head+cnt-1)%capacity]; } / Checks whether the circular queue is empty or not. */ bool isEmpty() { return cnt==0; } / Checks whether the circular queue is full or not. */ bool isFull() { return cnt==capacity; } private: int capacity; int head; int cnt; vector<int> queue; }; / * Your MyCircularQueue object will be instantiated and called as such: * MyCircularQueue* obj = new MyCircularQueue(k); * bool param_1 = obj->enQueue(value); * bool param_2 = obj->deQueue(); * int param_3 = obj->Front(); * int param_4 = obj->Rear(); * bool param_5 = obj->isEmpty(); * bool param_6 = obj->isFull(); */ 【摘要】 本文深入探讨了基于循环数组的无锁队列的原理和优势。传统的队列实现通常使用锁来保护共享资源,但这可能导致性能瓶颈和可伸缩性问题。为了克服这些限制,无锁队列应运而生。基于循环数组的无锁队列是一种经典的实现方式,通过采用特殊的算法和数据结构,多个线程可以并发地访问队列,而无需使用锁来保护共享资源。
在计算机科学领域,队列是一种常见的数据结构,用于在多线程或多进程环境中进行有效的消息传递和任务调度。然而,传统的队列实现通常使用锁来保护共享资源,这可能导致性能瓶颈和可伸缩性问题。
为了克服这些限制,无锁队列应运而生。无锁队列通过采用特殊的算法和数据结构,使多个线程可以并发地访问队列,而无需使用锁来保护共享资源。其中,基于循环数组的无锁队列是一种经典的实现方式。
本文将深入探讨基于循环数组的无锁队列的原理和优势。我们将介绍循环数组的基本概念,并解释如何通过适当的算法和技术实现无锁性。通过对比传统的锁保护队列和无锁队列,我们将揭示无锁队列的性能提升和可伸缩性优势。
此外,我们还将探讨基于循环数组的无锁队列在实际应用中的挑战和注意事项。我们将分享一些实际案例和经验教训,帮助读者更好地理解和应用无锁队列。
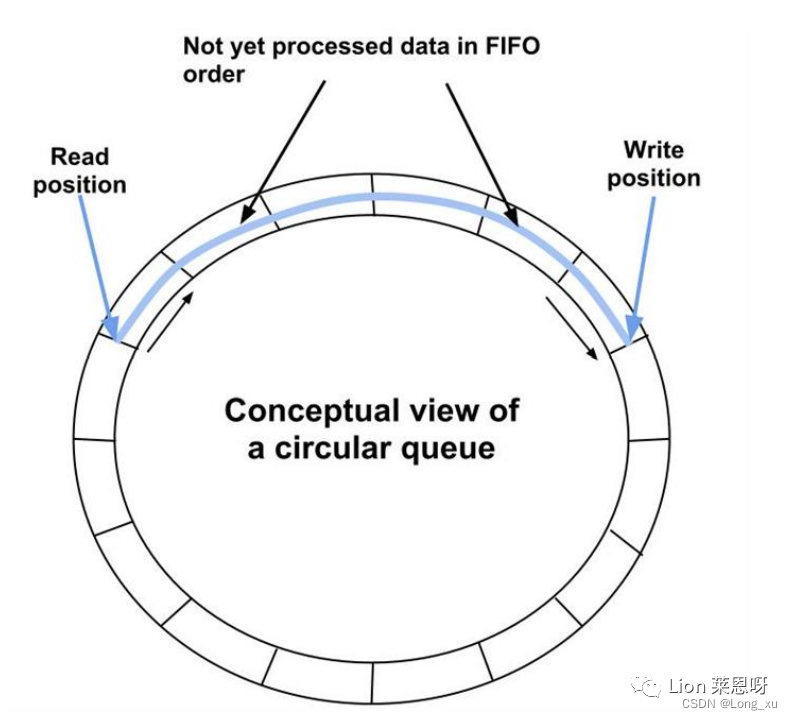
#ifndef _ARRAYLOCKFREEQUEUE_H___ #define _ARRAYLOCKFREEQUEUE_H___ #include <stdint.h> #ifdef _WIN64 #define QUEUE_INT int64_t #else #define QUEUE_INT unsigned long #endif #define ARRAY_LOCK_FREE_Q_DEFAULT_SIZE 65535 // 2^16 template <typename ELEM_T, QUEUE_INT Q_SIZE = ARRAY_LOCK_FREE_Q_DEFAULT_SIZE> class ArrayLockFreeQueue { public: ArrayLockFreeQueue(); virtual ~ArrayLockFreeQueue(); QUEUE_INT size(); bool enqueue(const ELEM_T &a_data);//入队 bool dequeue(ELEM_T &a_data);// 出队 bool try_dequeue(ELEM_T &a_data);//尝试入队 private: ELEM_T m_thequeue[Q_SIZE]; volatile QUEUE_INT m_count;//队列的元素个数 volatile QUEUE_INT m_writeIndex;//新元素入队时存放位置在数组中的下标 volatile QUEUE_INT m_readIndex;//下一个出队元素在数组中的下标 volatile QUEUE_INT m_maximumReadIndex;// 最后一个已经完成入队操作的元素在数组中的下标 inline QUEUE_INT countToIndex(QUEUE_INT a_count); }; #include "ArrayLockFreeQueueImp.h" #endif m_maximumReadIndex: 最后一个已经完成入列操作的元素在数组中的下标。如果它的值跟m_writeIndex不一致,表明有写请求尚未完成。这意味着,有写请求成功申请了空间但数据还没完全写进队列。所以如果有线程要读取,必须要等到写线程将数据完全写入到队列之后。
必须指明的是使用3种不同的下标都是必须的,因为队列允许任意数量的生产者和消费者围绕着它工作。
使用gcc内置的syn_bool_compare_and_swap,但重新做了宏定义封装。
#ifndef _ATOM_OPT_H___ #define _ATOM_OPT_H___ #ifdef __GNUC__ #define CAS(a_ptr, a_oldVal, a_newVal) __sync_bool_compare_and_swap(a_ptr, a_oldVal, a_newVal) #define AtomicAdd(a_ptr,a_count) __sync_fetch_and_add (a_ptr, a_count) #define AtomicSub(a_ptr,a_count) __sync_fetch_and_sub (a_ptr, a_count) #include <sched.h> // sched_yield() #else #include <Windows.h> #ifdef _WIN64 #define CAS(a_ptr, a_oldVal, a_newVal) (a_oldVal == InterlockedCompareExchange64(a_ptr, a_newVal, a_oldVal)) #define sched_yield() SwitchToThread() #define AtomicAdd(a_ptr, num) InterlockedIncrement64(a_ptr) #define AtomicSub(a_ptr, num) InterlockedDecrement64(a_ptr) #else #define CAS(a_ptr, a_oldVal, a_newVal) (a_oldVal == InterlockedCompareExchange(a_ptr, a_newVal, a_oldVal)) #define sched_yield() SwitchToThread() #define AtomicAdd(a_ptr, num) InterlockedIncrement(a_ptr) #define AtomicSub(a_ptr, num) InterlockedDecrement(a_ptr) #endif #endif #endif template <typename ELEM_T, QUEUE_INT Q_SIZE> inline QUEUE_INT ArrayLockFreeQueue<ELEM_T, Q_SIZE>::countToIndex(QUEUE_INT a_count) { return (a_count % Q_SIZE); // 取余的时候 } template <typename ELEM_T, QUEUE_INT Q_SIZE> bool ArrayLockFreeQueue<ELEM_T, Q_SIZE>::enqueue(const ELEM_T &a_data) { QUEUE_INT currentWriteIndex; // 获取写指针的位置 QUEUE_INT currentReadIndex; // 1. 获取可写入的位置 do { currentWriteIndex = m_writeIndex; currentReadIndex = m_readIndex; if(countToIndex(currentWriteIndex + 1) == countToIndex(currentReadIndex)) { return false; // 队列已经满了 } // 目的是为了获取一个能写入的位置 } while(!CAS(&m_writeIndex, currentWriteIndex, (currentWriteIndex+1))); // 获取写入位置后 currentWriteIndex 是一个临时变量,保存我们写入的位置 // We know now that this index is reserved for us. Use it to save the data m_thequeue[countToIndex(currentWriteIndex)] = a_data; // 把数据更新到对应的位置 // 2. 更新可读的位置,按着m_maximumReadIndex+1的操作 // update the maximum read index after saving the data. It wouldn't fail if there is only one thread // inserting in the queue. It might fail if there are more than 1 producer threads because this // operation has to be done in the same order as the previous CAS while(!CAS(&m_maximumReadIndex, currentWriteIndex, (currentWriteIndex + 1))) { // this is a good place to yield the thread in case there are more // software threads than hardware processors and you have more // than 1 producer thread // have a look at sched_yield (POSIX.1b) sched_yield(); // 当线程超过cpu核数的时候如果不让出cpu导致一直循环在此。 } AtomicAdd(&m_count, 1); return true; } 分析:
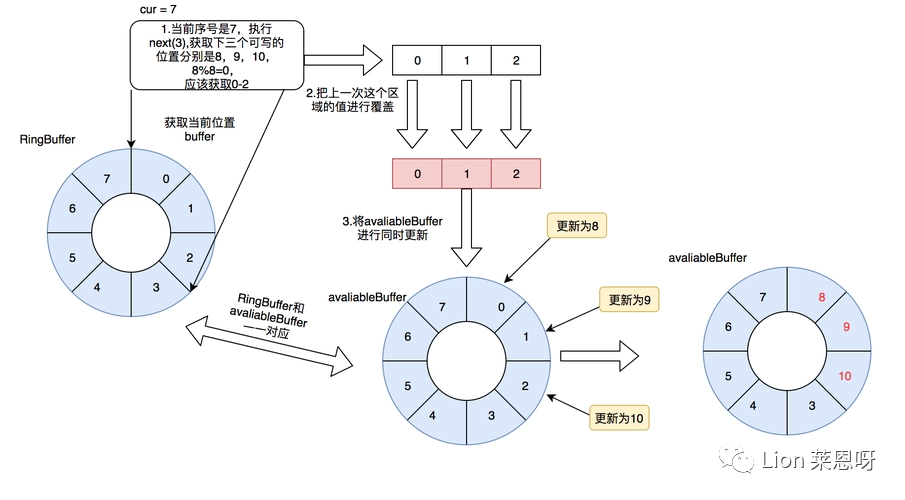
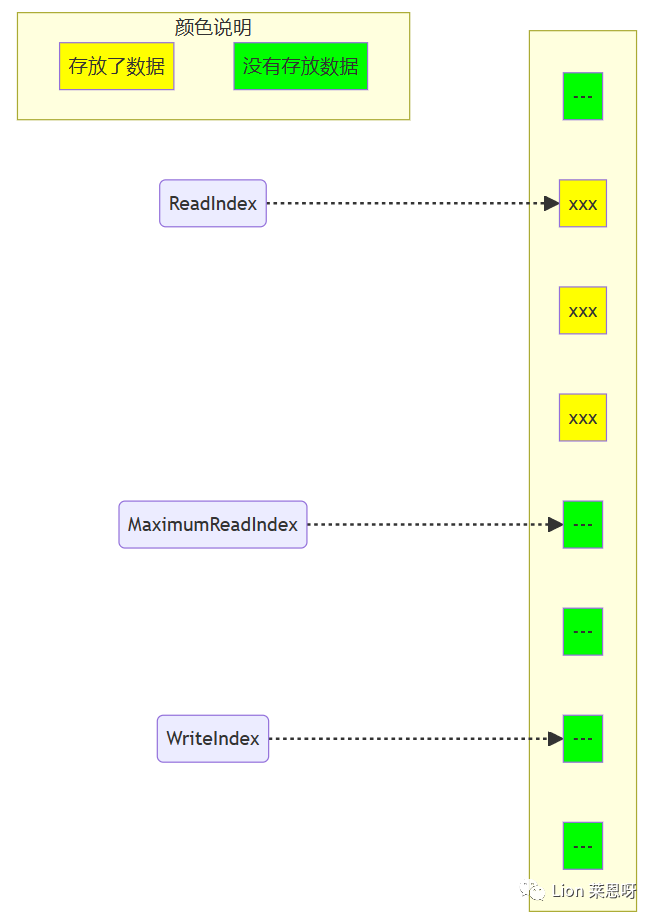
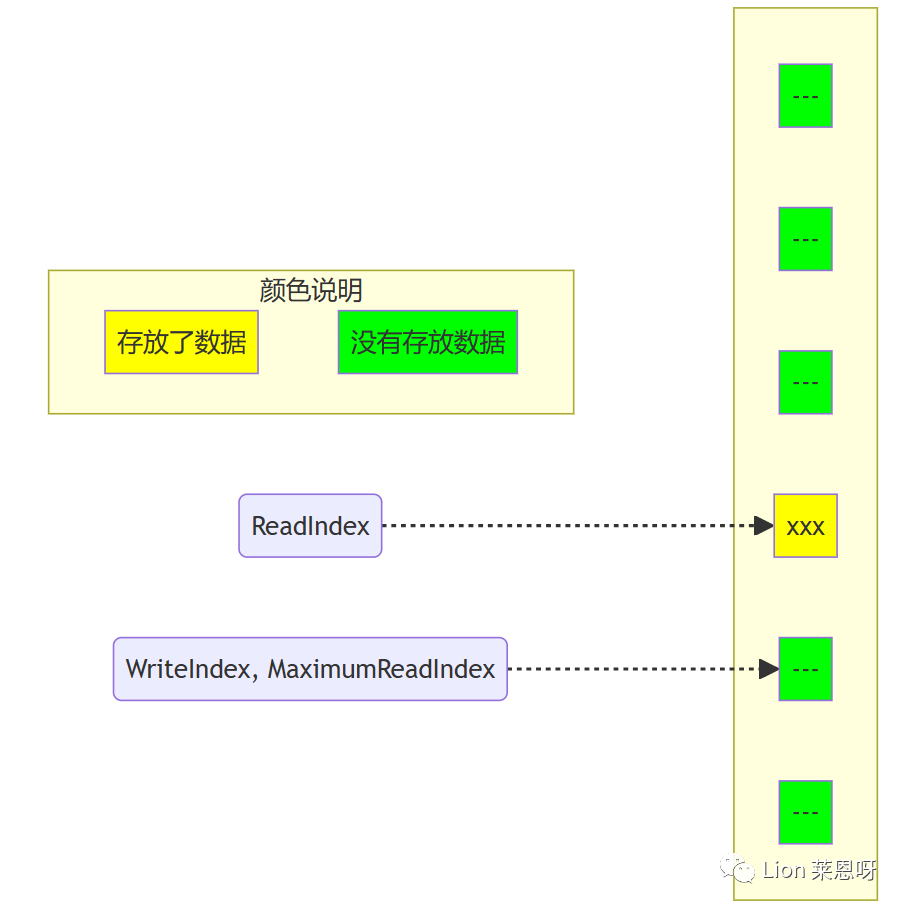
(1)对于下图,队列中存放了两个元素。WriteIndex指示的位置是新元素将会被插入的位置。ReadIndex指向的位置中的元素将会在下一次pop操作中被弹出。
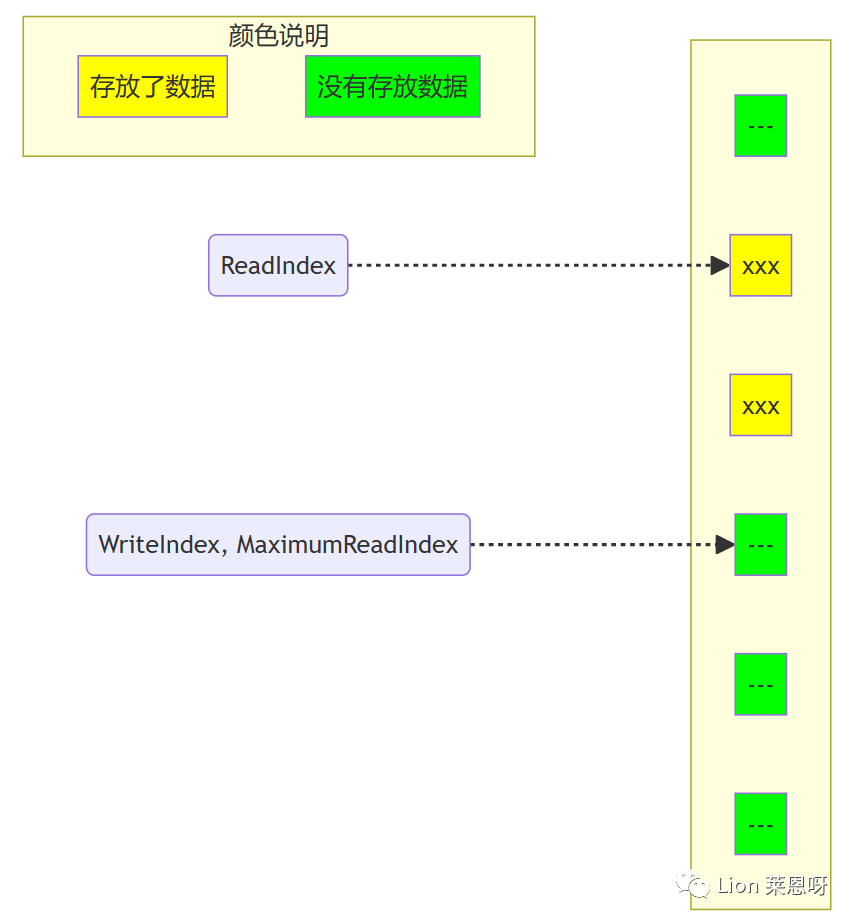
(2)当生产者准备将数据插入到队列中,它首先通过增加WriteIndex的值来申请空间。MaximumReadIndex指向最后一个存放有效数据的位置(也就是实际的队列尾)。
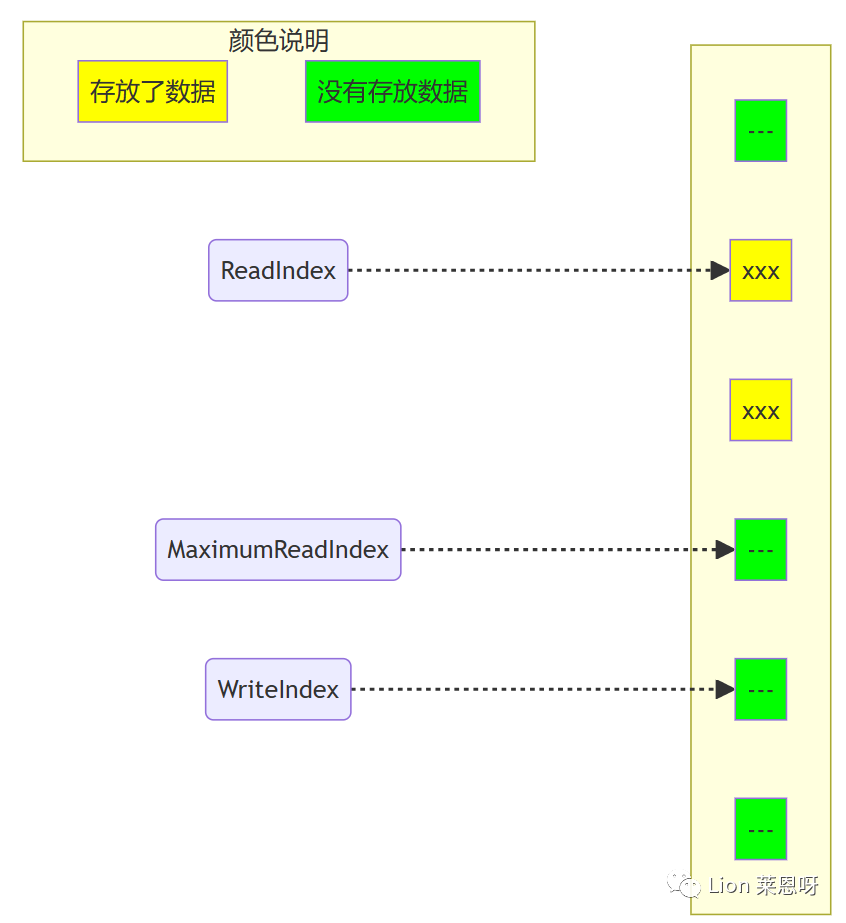
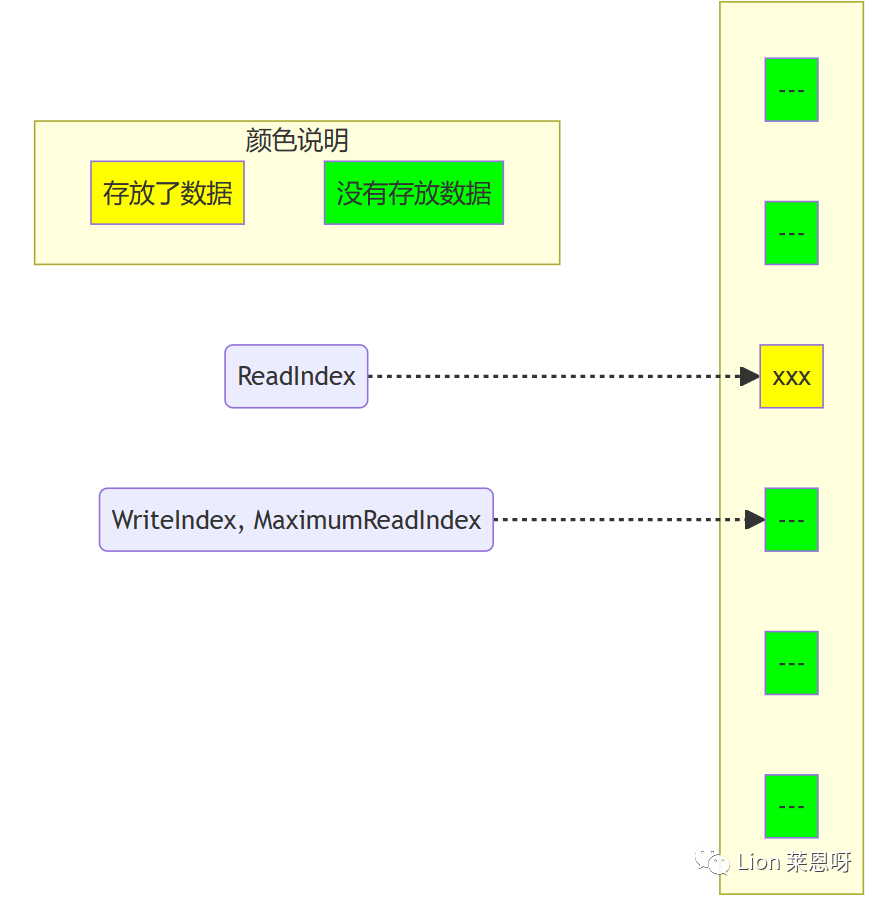
(3)一旦空间的申请完成,生产者就可以将数据拷贝到刚刚申请到的位置中。完成之后增加MaximumReadIndex使得它与WriteIndex的一致。
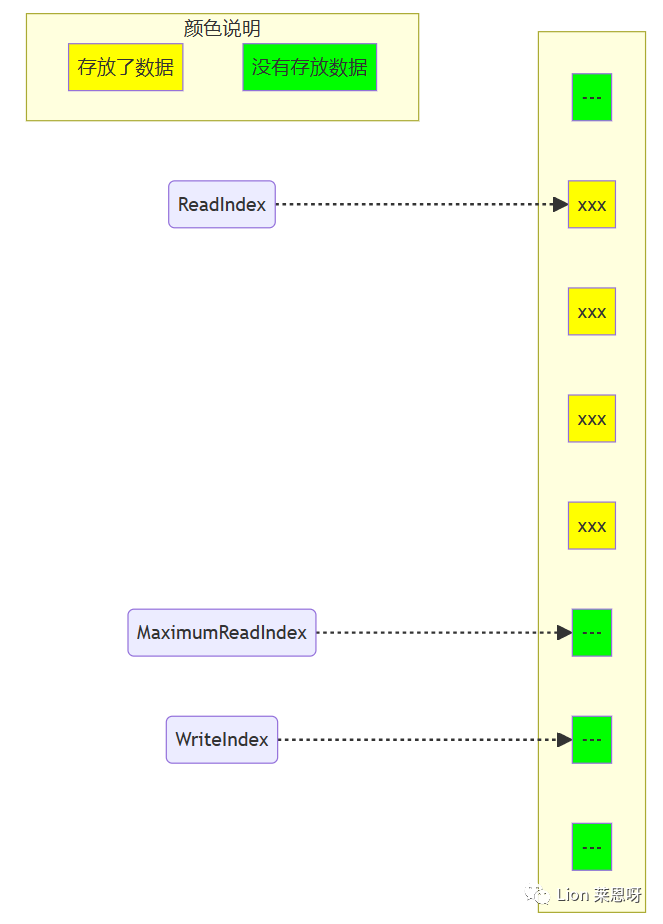
(4)现在队列中有3个元素,接着又有一个生产者尝试向队列中插入元素。
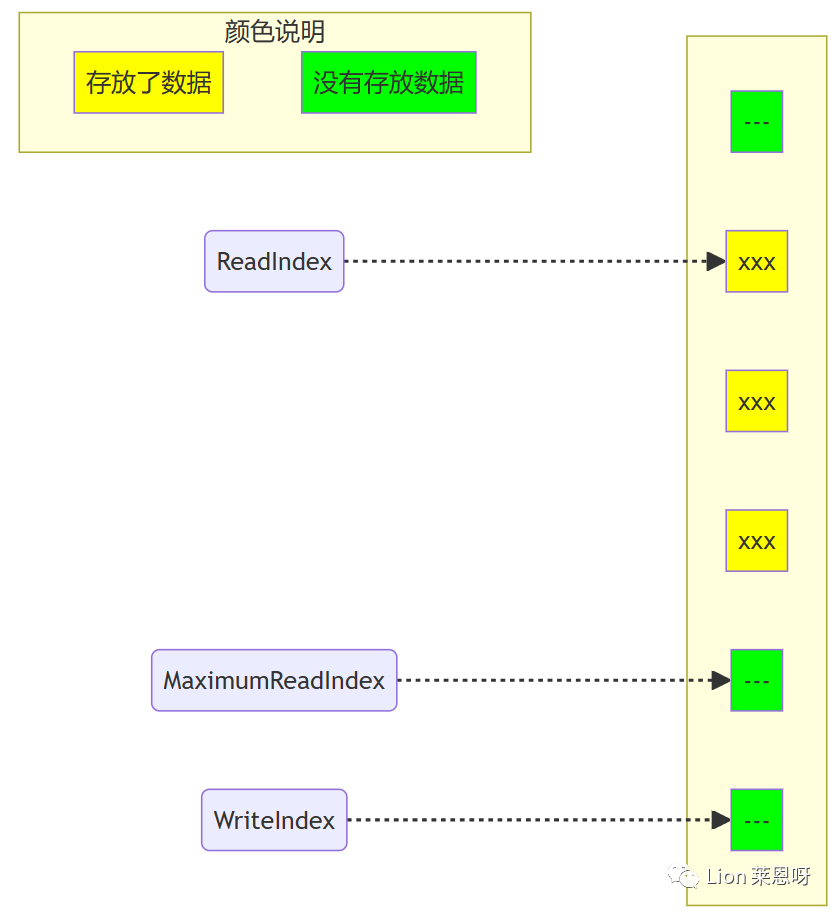
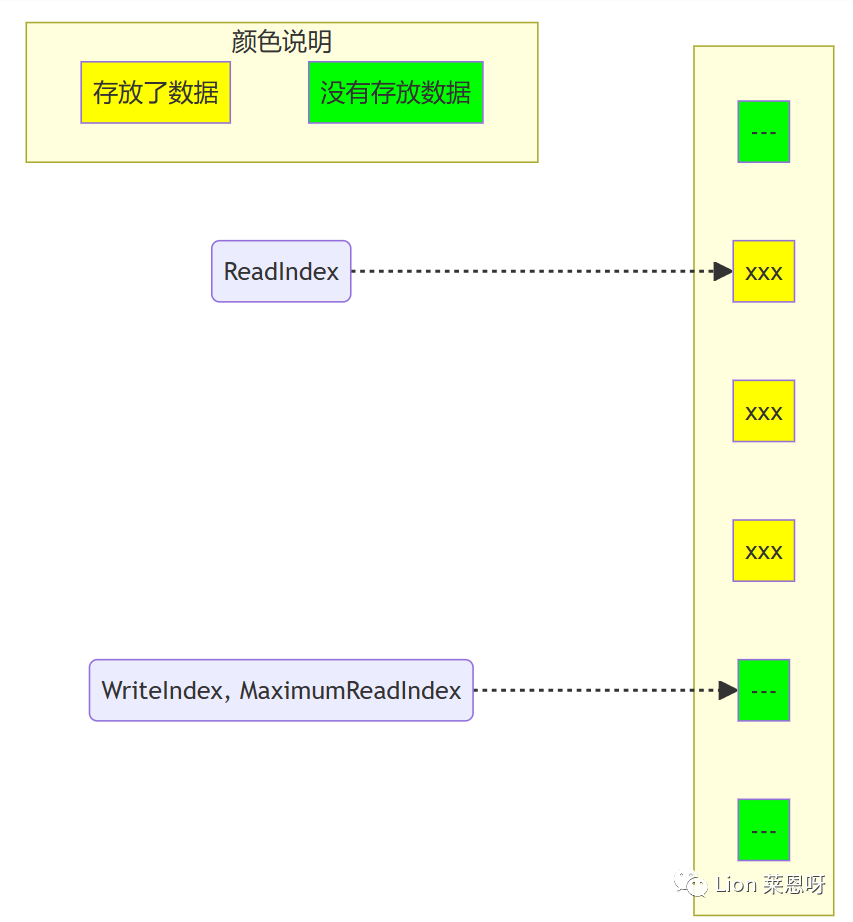
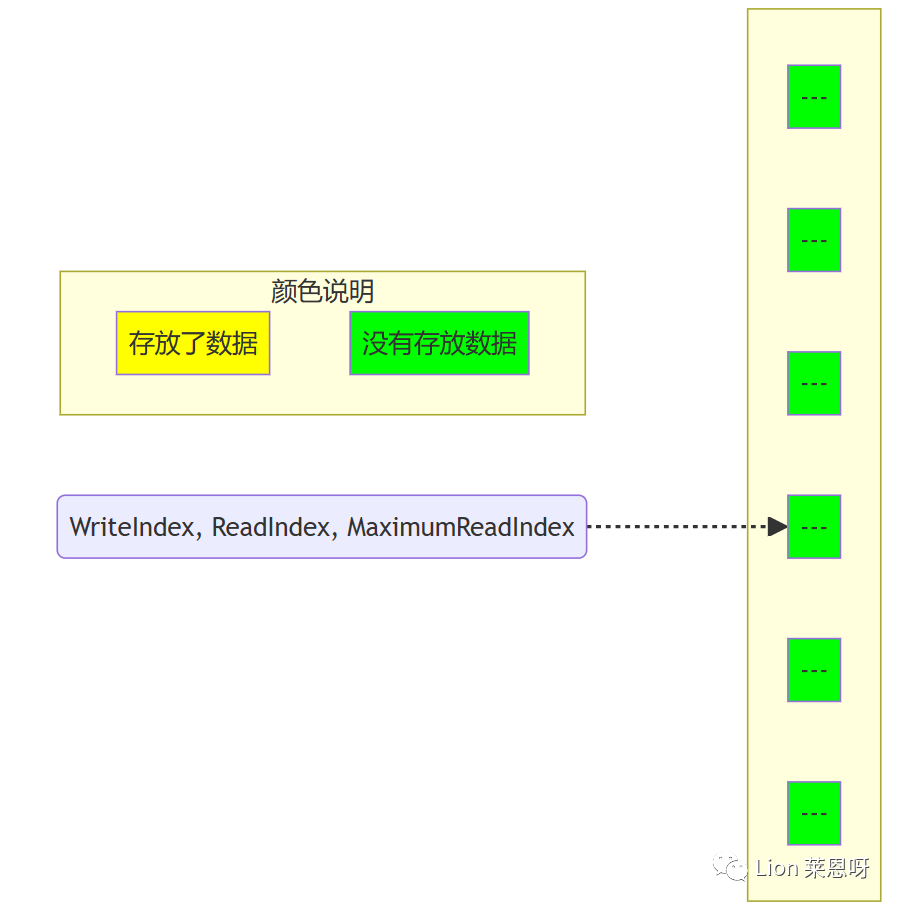
(5)在第一个生产者完成数据拷贝之前,又有另外一个生产者申请了一个新的空间准备拷贝数据。现在有两个生产者同时向队列插入数据。
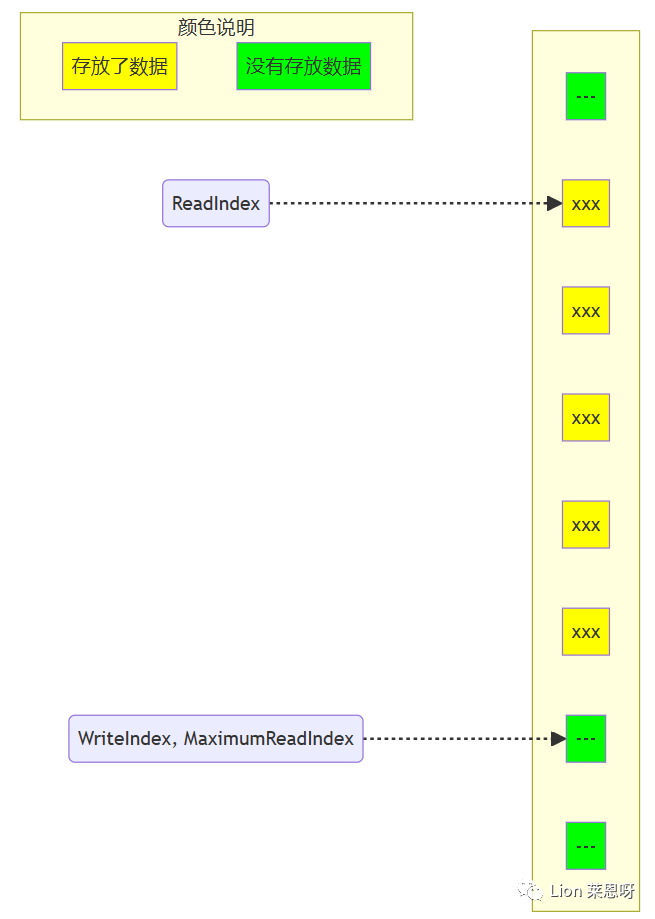
(7)现在第二个生产者可以递增MaximumReadIndex了;第二个生产者完成了对MaximumReadIndex的递增,现在队列中有5个元素。
template <typename ELEM_T, QUEUE_INT Q_SIZE> bool ArrayLockFreeQueue<ELEM_T, Q_SIZE>::dequeue(ELEM_T &a_data) { QUEUE_INT currentMaximumReadIndex; QUEUE_INT currentReadIndex; do { // to ensure thread-safety when there is more than 1 producer thread // a second index is defined (m_maximumReadIndex) currentReadIndex = m_readIndex; currentMaximumReadIndex = m_maximumReadIndex; if(countToIndex(currentReadIndex) == countToIndex(currentMaximumReadIndex)) // 如果不为空,获取到读索引的位置 { // the queue is empty or // a producer thread has allocate space in the queue but is // waiting to commit the data into it return false; } // retrieve the data from the queue a_data = m_thequeue[countToIndex(currentReadIndex)]; // 从临时位置读取的 // try to perfrom now the CAS operation on the read index. If we succeed // a_data already contains what m_readIndex pointed to before we // increased it if(CAS(&m_readIndex, currentReadIndex, (currentReadIndex + 1))) { AtomicSub(&m_count, 1); // 真正读取到了数据,元素-1 return true; } } while(true); assert(0); // Add this return statement to avoid compiler warnings return false; } 分析:
(1)以下插图展示了元素出列的时候各种下标是如何变化的,队列中初始有2个元素。WriteIndex指示的位置是新元素将会被插入的位置。ReadIndex指向的位置中的元素将会在下一次pop操作中被弹出。
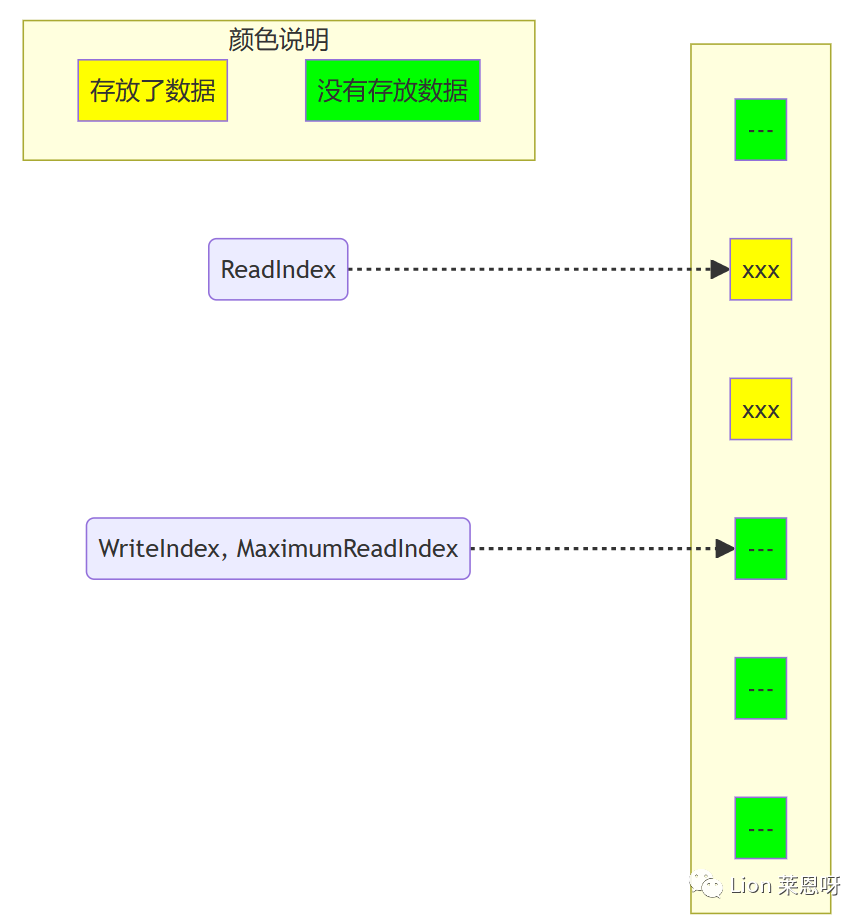
(2)消费者线程拷贝数组ReadIndex位置的元素,然后尝试用CAS操作将ReadIndex加1。如果操作成功消费者成功的将数据出列。因为CAS操作是原子的,所以只有唯一的线程可以在同一时刻更新ReadIndex的值。如果操作失败,读取新的ReadIndex值,以重复以上操作(copy数据,CAS)。
(3)现在又有一个消费者将元素出列,队列变成空。
(4)现在有一个生产者正在向队列中添加元素。它已经成功的申请了空间,但尚未完成数据拷贝。任何其它企图从队列中移除元素的消费者都会发现队列非空(因为writeIndex不等于readIndex)。但它不能读取readIndex所指向位置中的数据,因为readIndex与MaximumReadIndex相等。消费者将会在do循环中不断的反复尝试,直到生产者完成数据拷贝增加MaximumReadIndex的值,或者队列变成空(这在多个消费者的场景下会发生)。
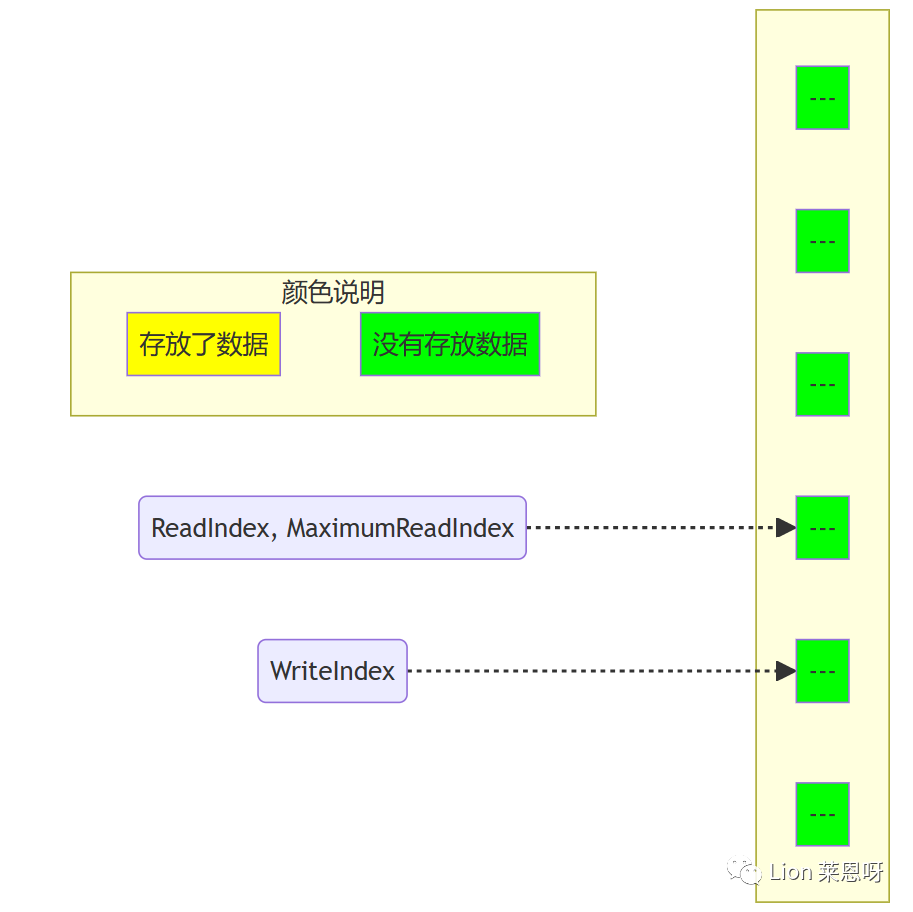
(5)当生产者完成数据拷贝,队列的大小是1,消费者线程可以读取这个数据了。
enqueue函数中使用了sched_yiedld()来主动的让出CPU,对于一个无锁的算法而言,这个调用看起来有点奇怪。
多线程环境下影响性能的其中一个因素就是Cache损坏。而产生Cache损坏的一种情况就是一个线程被抢占,操作系统需要保存被抢占线程的上下文,然后将被选中作为下一个调度线程的上下文载入。此时Cache中缓存的数据都会失效,因为它是被抢占线程的数据而不是新线程的数据。
所以,当此算法调用sched_yield()意味着告诉操作系统:“我要把处理器时间让给其它线程,因为我要等待某件事情的发生”。无锁算法和通过阻塞机制同步的算法的一个主要区别在于无锁算法不会阻塞在线程同步上。
那么为什么在这里我们要主动请求操作系统抢占自己呢? 它与有多少个生产者线程在并发的往队列中存放数据有关:每个生产者线程所执行的CAS操作都必须严格遵循FIFO次序,一个用于申请空间,另一个用于通知消费者数据已经写入完成可以被读取了。
如果应用程序只有唯一的生产者操作这个队列,sche_yield()将永远没有机会被调用,第2个CAS操作永远不会失败。因为在一个生产者的情况下没有人能破坏生产者执行这两个CAS操作的FIFO顺序。
而当多于一个生产者线程往队列中存放数据的时候,问题就出现了。概括来说,一个生产者通过第1个
CAS操作申请空间,然后将数据写入到申请到的空间中,然后执行第2个CAS操作通知消费者数据准备完毕可供读取了。这第2个CAS操作必须遵循FIFO顺序,也就是说,如果A线程第首先执行完第一个CAS操作,那么它也要第1个执行完第2个CAS操作,如果A线程在执行完第一个CAS操作之后停止,然后B线程执行完第1个CAS操作,那么B线程将无法完成第2个CAS操作,因为它要等待A先完成第2个CAS操作。而这就是问题产生的根源。
#ifndef _ARRAYLOCKFREEQUEUEIMP_H___ #define _ARRAYLOCKFREEQUEUEIMP_H___ #include "ArrayLockFreeQueue.h" #include <assert.h> #include "atom_opt.h" template <typename ELEM_T, QUEUE_INT Q_SIZE> ArrayLockFreeQueue<ELEM_T, Q_SIZE>::ArrayLockFreeQueue() : m_writeIndex(0), m_readIndex(0), m_maximumReadIndex(0) { m_count = 0; } template <typename ELEM_T, QUEUE_INT Q_SIZE> ArrayLockFreeQueue<ELEM_T, Q_SIZE>::~ArrayLockFreeQueue() { } template <typename ELEM_T, QUEUE_INT Q_SIZE> inline QUEUE_INT ArrayLockFreeQueue<ELEM_T, Q_SIZE>::countToIndex(QUEUE_INT a_count) { return (a_count % Q_SIZE); // 取余的时候 } template <typename ELEM_T, QUEUE_INT Q_SIZE> QUEUE_INT ArrayLockFreeQueue<ELEM_T, Q_SIZE>::size() { QUEUE_INT currentWriteIndex = m_writeIndex; QUEUE_INT currentReadIndex = m_readIndex; if(currentWriteIndex>=currentReadIndex) return currentWriteIndex - currentReadIndex; else return Q_SIZE + currentWriteIndex - currentReadIndex; } template <typename ELEM_T, QUEUE_INT Q_SIZE> bool ArrayLockFreeQueue<ELEM_T, Q_SIZE>::enqueue(const ELEM_T &a_data) { QUEUE_INT currentWriteIndex; // 获取写指针的位置 QUEUE_INT currentReadIndex; // 1. 获取可写入的位置 do { currentWriteIndex = m_writeIndex; currentReadIndex = m_readIndex; if(countToIndex(currentWriteIndex + 1) == countToIndex(currentReadIndex)) { return false; // 队列已经满了 } // 目的是为了获取一个能写入的位置 } while(!CAS(&m_writeIndex, currentWriteIndex, (currentWriteIndex+1))); // 获取写入位置后 currentWriteIndex 是一个临时变量,保存我们写入的位置 // We know now that this index is reserved for us. Use it to save the data m_thequeue[countToIndex(currentWriteIndex)] = a_data; // 把数据更新到对应的位置 // 2. 更新可读的位置,按着m_maximumReadIndex+1的操作 // update the maximum read index after saving the data. It wouldn't fail if there is only one thread // inserting in the queue. It might fail if there are more than 1 producer threads because this // operation has to be done in the same order as the previous CAS while(!CAS(&m_maximumReadIndex, currentWriteIndex, (currentWriteIndex + 1))) { // this is a good place to yield the thread in case there are more // software threads than hardware processors and you have more // than 1 producer thread // have a look at sched_yield (POSIX.1b) sched_yield(); // 当线程超过cpu核数的时候如果不让出cpu导致一直循环在此。 } AtomicAdd(&m_count, 1); return true; } template <typename ELEM_T, QUEUE_INT Q_SIZE> bool ArrayLockFreeQueue<ELEM_T, Q_SIZE>::try_dequeue(ELEM_T &a_data) { return dequeue(a_data); } template <typename ELEM_T, QUEUE_INT Q_SIZE> bool ArrayLockFreeQueue<ELEM_T, Q_SIZE>::dequeue(ELEM_T &a_data) { QUEUE_INT currentMaximumReadIndex; QUEUE_INT currentReadIndex; do { // to ensure thread-safety when there is more than 1 producer thread // a second index is defined (m_maximumReadIndex) currentReadIndex = m_readIndex; currentMaximumReadIndex = m_maximumReadIndex; if(countToIndex(currentReadIndex) == countToIndex(currentMaximumReadIndex)) // 如果不为空,获取到读索引的位置 { // the queue is empty or // a producer thread has allocate space in the queue but is // waiting to commit the data into it return false; } // retrieve the data from the queue a_data = m_thequeue[countToIndex(currentReadIndex)]; // 从临时位置读取的 // try to perfrom now the CAS operation on the read index. If we succeed // a_data already contains what m_readIndex pointed to before we // increased it if(CAS(&m_readIndex, currentReadIndex, (currentReadIndex + 1))) { AtomicSub(&m_count, 1); // 真正读取到了数据,元素-1 return true; } } while(true); assert(0); // Add this return statement to avoid compiler warnings return false; } #endif #include "ArrayLockFreeQueue.h" ArrayLockFreeQueue<int> arraylockfreequeue; void *arraylockfreequeue_producer_thread(void *argv) { PRINT_THREAD_INTO(); int count = 0; int write_failed_count = 0; for (int i = 0; i < s_queue_item_num;) { if (arraylockfreequeue.enqueue(count)) // enqueue的顺序是无法保证的,我们只能计算enqueue的个数 { count = lxx_atomic_add(&s_count_push, 1); i++; } else { write_failed_count++; // printf("%s %lu enqueue failed, q:%d\n", __FUNCTION__, pthread_self(), arraylockfreequeue.size()); sched_yield(); // usleep(10000); } } // printf("%s %lu write_failed_count:%d\n", __FUNCTION__, pthread_self(), write_failed_count) PRINT_THREAD_LEAVE(); return NULL; } void *arraylockfreequeue_consumer_thread(void *argv) { int last_value = 0; PRINT_THREAD_INTO(); int value = 0; int read_failed_count = 0; while (true) { if (arraylockfreequeue.dequeue(value)) { if (s_consumer_thread_num == 1 && s_producer_thread_num == 1 && (last_value + 1) != value) // 只有一入一出的情况下才有对比意义 { // printf("pid:%lu, -> value:%d, expected:%d\n", pthread_self(), value, last_value); } lxx_atomic_add(&s_count_pop, 1); last_value = value; } else { read_failed_count++; // printf("%s %lu no data, s_count_pop:%d, value:%d\n", __FUNCTION__, pthread_self(), s_count_pop, value); // usleep(100); sched_yield(); } if (s_count_pop >= s_queue_item_num * s_producer_thread_num) { // printf("%s dequeue:%d, s_count_pop:%d, %d, %d\n", __FUNCTION__, last_value, s_count_pop, s_queue_item_num, s_consumer_thread_num); break; } } // printf("%s %lu read_failed_count:%d\n", __FUNCTION__, pthread_self(), read_failed_count) PRINT_THREAD_LEAVE(); return NULL; } - 基于循环数组的无锁队列ArrayLockFreeQueue相实现对简单。
- 无锁消息队列适用于10w+每秒的数据吞吐以及数据操作耗时较少场景。
- currentMaximumReadIndex表示其之前的数据可以读取,本身所在的位置不可读取。
欢迎关注公众号《Lion 莱恩呀》学习技术,每日推送文章。

介绍一个<零声教育>的系统学习,对c/c++linux系统提升感兴趣的读者可点击链接了解:白金学习卡(含基础架构、高性能存储、golang云原生、音视频、Linux内核等)。
//竞赛都用静态分配 #include "https://www.zhihu.com/topic/bits/stdc++.h" using namespace std; #define N 1003 int Hash[N]; struct myqueue{ int data[N];//静态分配 如果是动态分配 int* data; int head,rear; bool init(){//初始化 //如果是动态分配 //Q.data = (int *) malloc(N * sizeof(int)); //if(!Q.data) return false; head = rear = 0; return true; } int size(){return (rear - head + N) % N;}//返回队列长度 bool empty(){//判断队列是否为空 if(size() == 0) return true; else return false; } bool push(int e){//队尾插入新元素,新的rear指向新元素(下一个)的位置 if((rear + 1) % N == head) return false;//队列满了 data[rear] = e; rear = (rear + 1) % N; return true; } bool pop(){//删除队头元素,并返回它 if(empty()) return false; int res = data[head]; head = (head + 1) % N; return true; } int front(){return data[head];}//返回队首,但是不删除 }Q; int main(){ Q.init(); int m,n; cin >> m >> n; int cnt = 0; while(n--){ int en; cin >> en; if(!Hash[en]){ ++cnt; Q.push(en); Hash[en] = 1; while (Q.size() > m){ int tmp; Q.pop(tmp); Hash[tmp] = 0; } } } cout << cnt << "\n"; return 0; }本实验通过C++实现了循环队列的存储。在这个过程中,实验使用一个固定大小的数组来存储元素,并通过两个指针(front 和 rear)来管理队列中的数据。该程序提供了初始化、销毁、清空、判断队列状态、读取队列长度、访问队头元素、入队和出队操作以及遍历队列的功能。
- 在队列结构中,采用静态链表的形式存储,可以在不浪费空间的情况下尽可能简化代码并提高队列操作效率。
#include<iostream> using namespace std; #define queuesize 10 typedef int elemtype; typedef struct queuetype { elemtype* base; int front, rear; //头和尾的数组下标 }queuetype; - 初始化函数中将数据基址开辟一块新的内存,而将队头和队尾的数组下标全部置为0.
//初始化循环队列 void InitQueue(queuetype* Q) { Q->base = new elemtype[queuesize]; Q->front = 0; Q->rear = 0; cout << "初始化成功!" << endl; }- 在销毁队列函数中释放数据基址的内存,且为了避免误操作增加了确认删除的交互方式。
//销毁循环队列 void DestroyQueue(queuetype* Q) { cout << "是否销毁?Y/N" << endl; char YesOrNo; cin >> YesOrNo; if (YesOrNo == 'Y') { delete[] Q->base; cout << "销毁成功!" << endl; } }- 在清空函数中将队头和队尾数组下标置为相等。
//清空循环队列 void ClearQueue(queuetype* Q) { cout << "是否清空?Y/N" << endl; char YesOrNo; cin >> YesOrNo; if (YesOrNo == 'Y') { Q->rear = Q->front; cout << "清空成功!" << endl; } }- 在判断队列状态函数中,通过数组下标对队列最大容量取余来判断是否为空/满。
读取队列长度函数中也用到了这种方法。
//判断是否为空 bool QueueEmpty(queuetype* Q) { if (Q->front == Q->rear)return true; else return false; } //判断是否为满 bool QueueFull(queuetype* Q) { if ((1 + Q->rear) % queuesize == Q->front)return true; else return false; } //此处浪费一个元素的内存空间,目的是将队满与队空状态区分。 //读取队列长度 int QueueLength(queuetype* Q) { if (QueueEmpty(Q))return 0; else return (Q->rear - Q->front + queuesize) % queuesize; }- 在返回队头元素中通过数组下标返回队头元素,不对队列进行其他操作。
入队操作中先将数据基址赋值后将队尾指针后移一位,确保队尾数组下标的位置为无效值(即为后续操作腾出空间)。
出队操作中先输出队头数组下标指向的元素,然后后移队头数组下标,确保队头数组下标的位置为队头(有效值)。
//返回队头元素 elemtype GetHead(queuetype* Q) { if (QueueEmpty(Q)) { cout << "返回队头元素失败!队空!" << endl; return NULL; } return Q->base[Q->front]; } //入队e void EnQueue(queuetype* Q, elemtype e) { if (QueueFull(Q)) { cout << "插入失败!队满!" << endl; return; } Q->base[Q->rear] = e; Q->rear = (Q->rear + 1) % queuesize; return; } //出队 elemtype DeQueue(queuetype* Q) { if (QueueEmpty(Q)) { cout << "出队失败!队空!" << endl; return NULL; } elemtype e = Q->base[Q->front]; Q->front = (Q->front + 1) % queuesize; return e; }- 通过逐次从队头访问一位元素后访问数组下标+1的方式遍历整个队列。
//遍历访问整个队列 void QueueTraverse(queuetype* Q) { if (QueueEmpty(Q) == true) { cout << "队空!" << endl; return; } int i = Q->front; while (i != Q->rear) { cout << Q->base[i] << " "; i = (i + 1) % queuesize; } cout << endl; return; }- 在主函数中,设计了交互系统。用户可以根据具体需求在数组内完成入队出队、获取队头元素、获取队列长度、清空/销毁队列等操作。
int main() { queuetype queue1; InitQueue(&queue1); while (1) { cout << "队列状态:"; QueueTraverse(&queue1); cout << "请选择: 1 入队; 2 出队; 3 队头元素; 4 队长; 5 清空; 6 销毁 & 退出." << endl; int order; cin >> order; switch (order) { case 1: { int e; cout << "入队元素为:"; cin >> e; EnQueue(&queue1, e); break; } case 2: { int e = DeQueue(&queue1); if(!QueueEmpty(&queue1))cout << "出队元素为:" << e << endl; break; } case 3: { cout << "队头元素为:" << GetHead(&queue1) << endl; break; } case 4: { cout << "队长为:" << QueueLength(&queue1) << endl; break; } case 5: { ClearQueue(&queue1); break; } case 6: { DestroyQueue(&queue1); return 0; } default:cout << "输入无效值!" << endl; } } return 0; }最终实验效果如下:

循环队列不仅能够充分发挥静态链表中插入和删除操作上速度较快、避免了内存泄漏和假溢出风险等优点,还能应用在树和图等更复杂数据结构的遍历上,使代码简化。但其缺点在于其固定的大小限制了它的灵活性,在此方面不及链队列。
通过本次实验,我们对循环队列的实现有了更深刻的了解。
主要是空队列和满队列的定义。空队列、满队列的定义没有死板的规定,这取决于开发者的定义。
代码里的规则:
空队列:头指针等于尾指针。
满队列:尾指针加1后等于头队列。
queue.h
#pragma once #include <Windows.h> #define QUEUE_VOLUME_LIMIT 0X1000 #pragma pack(1) typedef struct { int head; int tail; LPVOID e[QUEUE_VOLUME_LIMIT]; }CircleQueue; #pragma pack() class QueueClass { public: QueueClass(); ~QueueClass(); CircleQueue * m_queue = 0; int Enqueue(LPVOID v); int Dequeue(LPVOID* v); int Size(); };queue.cpp
#include "queue.h" QueueClass::QueueClass() { if (m_queue == 0) { m_queue = new CircleQueue(); m_queue->head = 0; m_queue->tail = 0; } } QueueClass::~QueueClass() { if (m_queue) { delete m_queue; } } int QueueClass::Dequeue(LPVOID * v) { if (m_queue->tail == m_queue->head) { return 0; } *v = m_queue->e[m_queue->head]; m_queue->head ++; if (m_queue->head >= QUEUE_VOLUME_LIMIT) { m_queue->head = 0; } return TRUE; } int QueueClass::Enqueue(LPVOID v) { if (m_queue->tail + 1 == QUEUE_VOLUME_LIMIT) { if ( m_queue->head == 0) { return 0; } else { m_queue->e[m_queue->tail] = v; m_queue->tail = 0; } } else { if (m_queue->tail + 1 == m_queue->head) { return 0; } else { m_queue->e[m_queue->tail] = v; m_queue->tail++; } } return TRUE; } int QueueClass::Size() { if (m_queue->tail > m_queue->head) { return m_queue->tail - m_queue->head; } else { return QUEUE_VOLUME_LIMIT - (m_queue->head - m_queue->tail); } }版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/bcyy/33775.html