
本文将详细介绍grep命令的使用方法及其实际应用场景,帮助大家快速掌握这款工具的精髓。欢迎大家分享转发,点个关注和在看吧!
什么是grep命令?
grep 是Linux中用于文本搜索的命令行工具,能够根据指定的模式(pattern)搜索文件中的内容,并显示符合条件的行。grep命令支持正则表达式,能灵活、高效地搜索复杂的文本模式。
1.基本语法
grep [选项] ‘模式’ 文件名
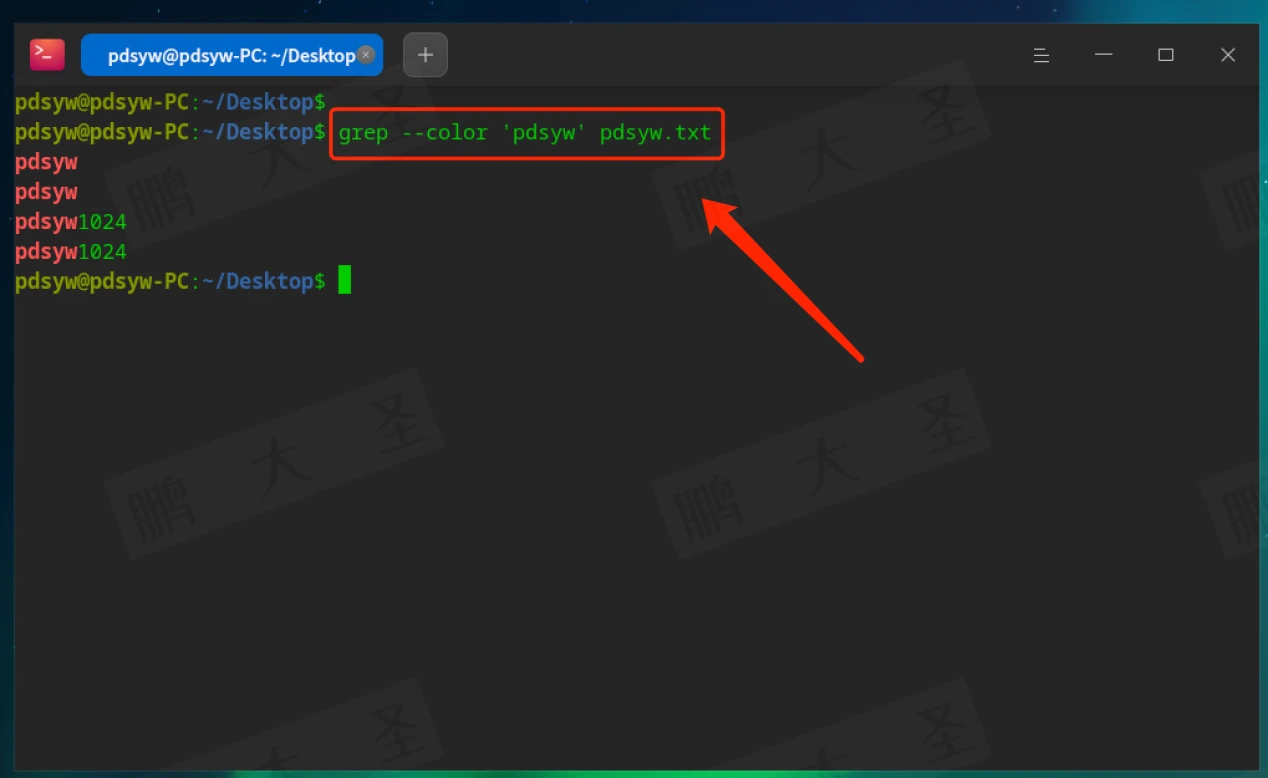
例如,在pdsyw.txt文件中查找包含“pdsyw”的行:
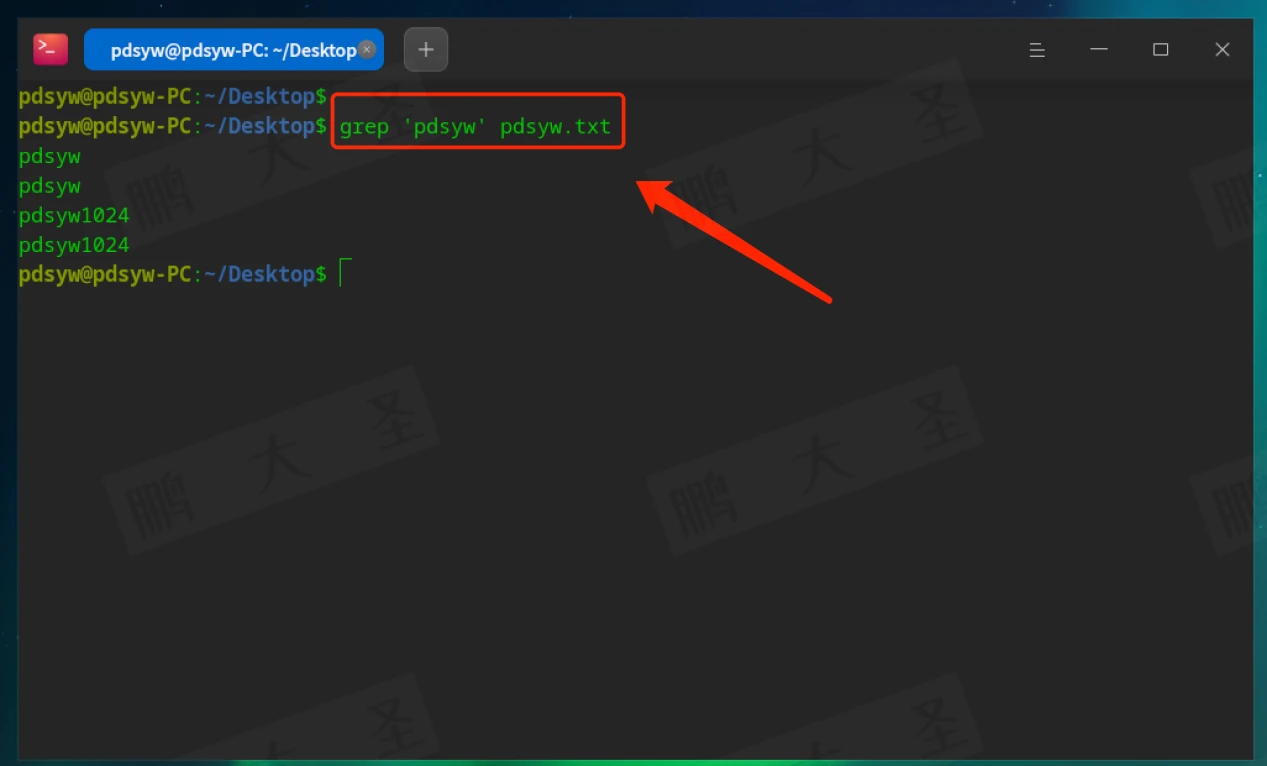
2.常用选项
-i:忽略大小写
搜索时忽略大小写,例如可以匹配pdsyw、PDSYW等。
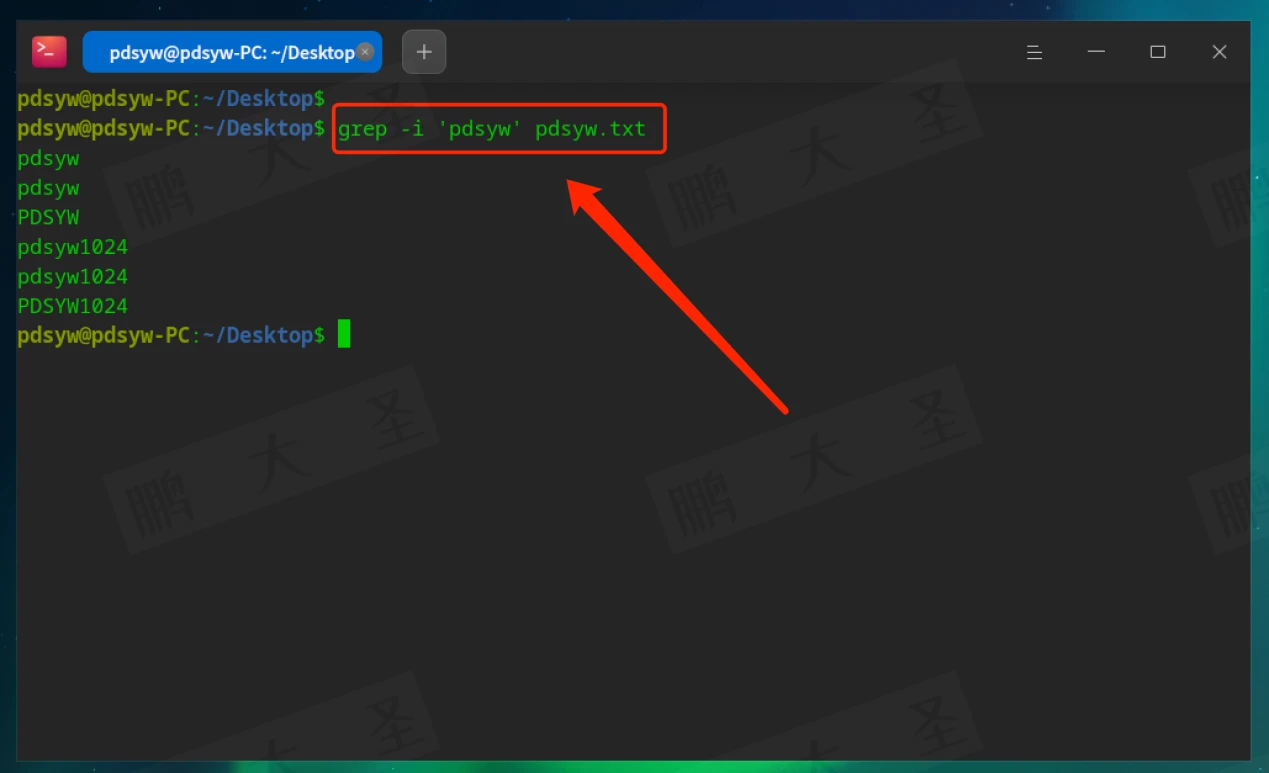
-v:反向匹配
显示不包含“pdsyw”的行。
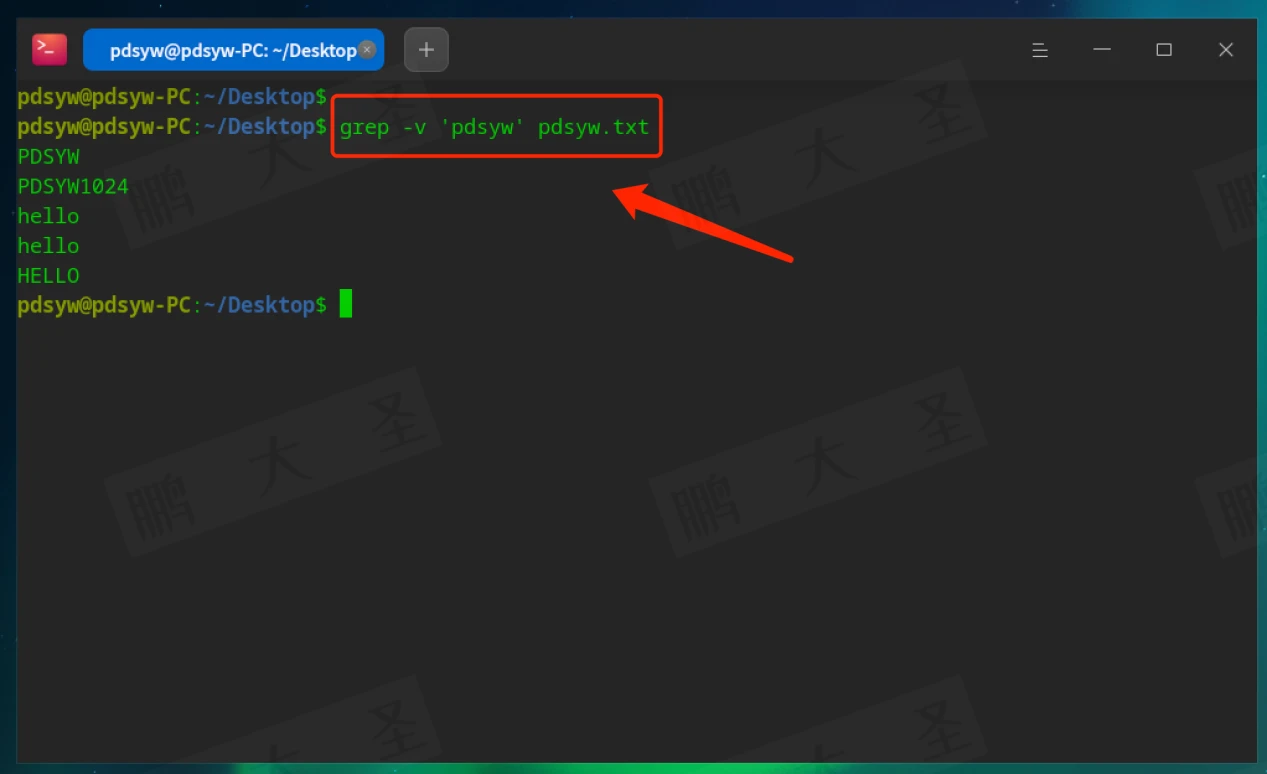
-c:只输出匹配的行数
输出文件中包含“pdsyw”的行数,而不是具体的内容。
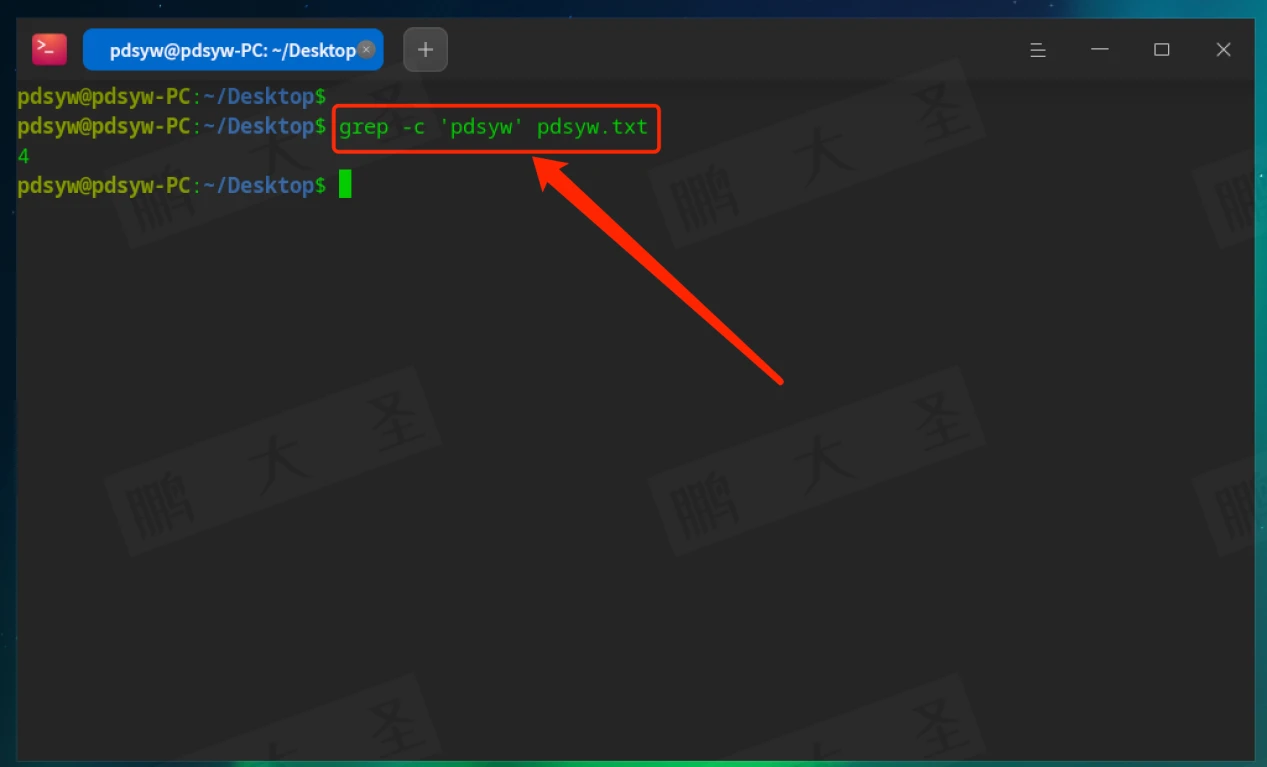
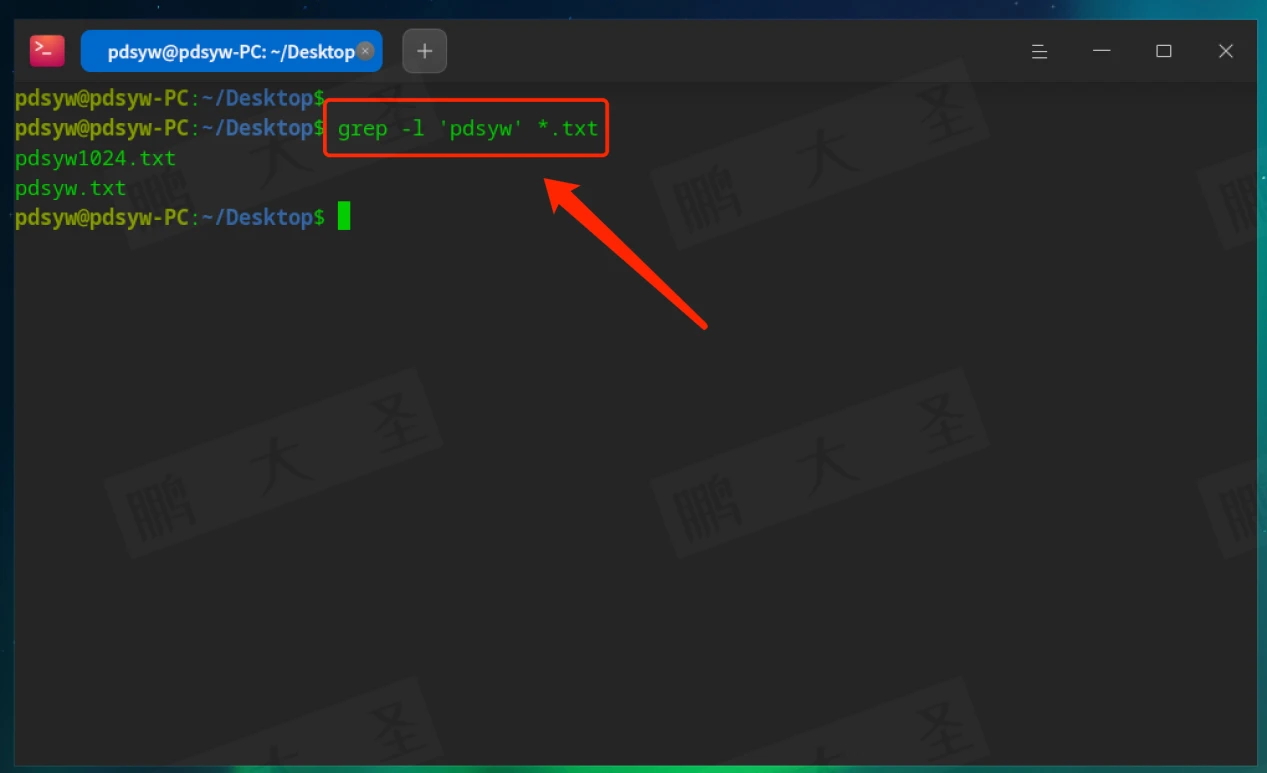
-l:仅显示包含匹配内容的文件名
在当前目录的所有.txt文件中查找包含“pdsyw”的文件名。
-L:仅显示不包含匹配内容的文件名
显示当前目录中不包含“pdsyw”的.txt文件。

-n:显示匹配行及其行号
显示包含“pdsyw”的行,并在前面显示行号。
-H:显示文件名(即使只有一个文件)
在输出匹配内容的同时,显示文件名。
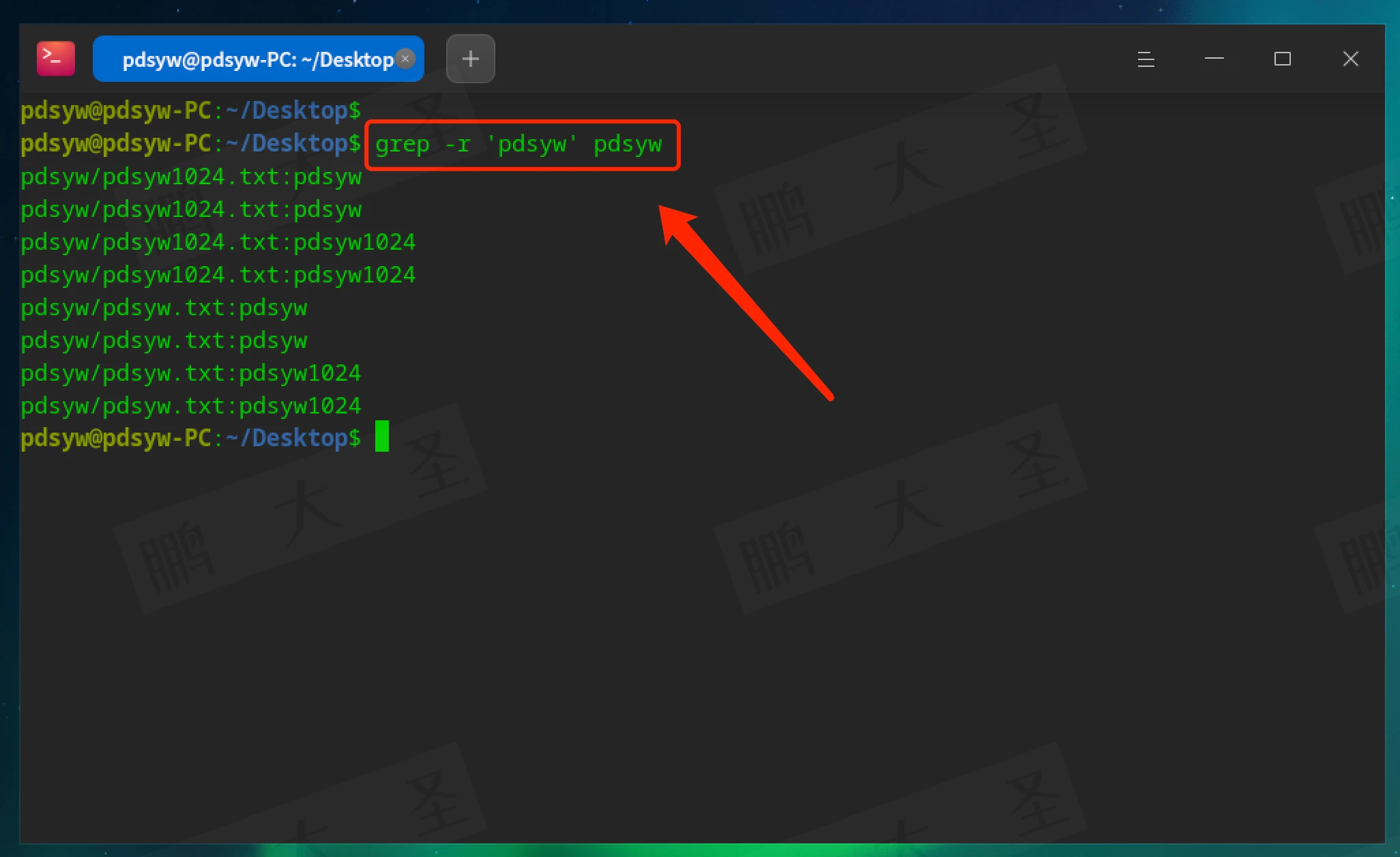
-r 或 -R:递归搜索目录
在指定目录及其子目录中的所有文件中查找包含“pdsyw”的行。
-w:匹配整个单词
匹配完整的单词pdsyw,不会匹配pdsywworld或pdsyw123等。
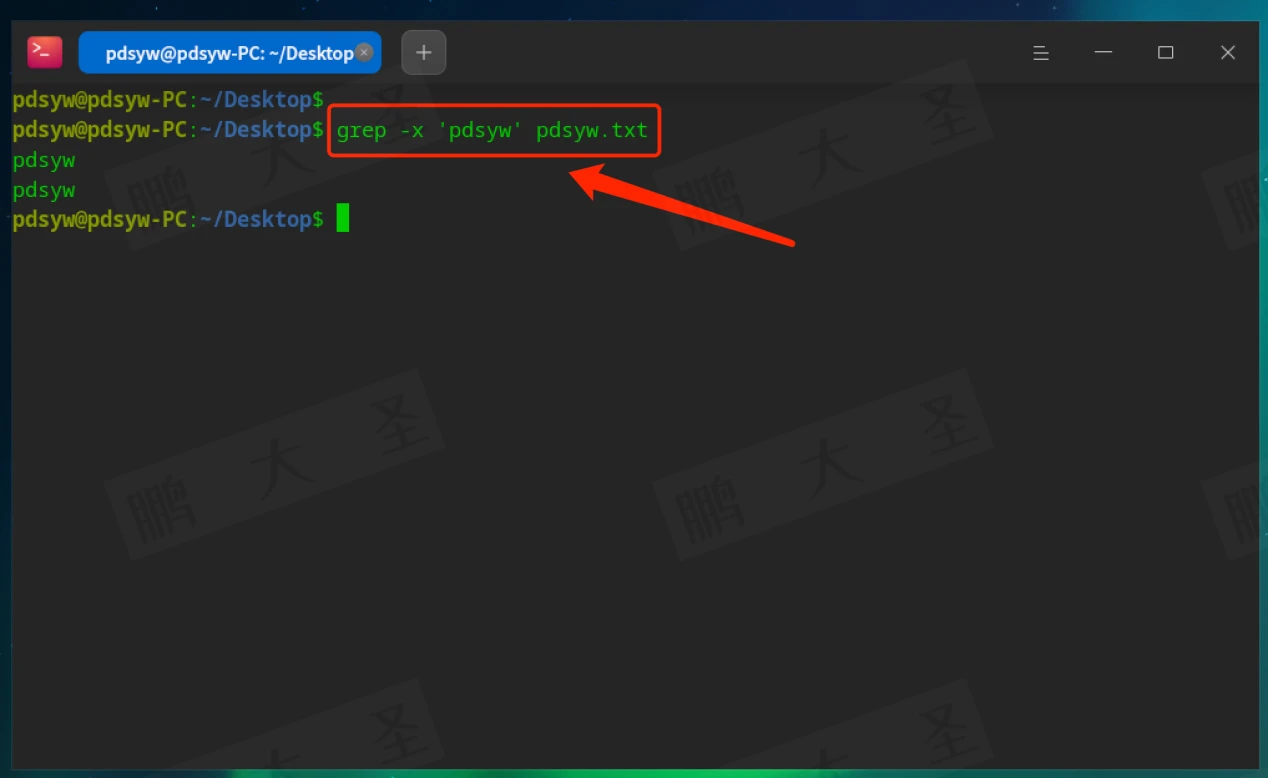
-x:匹配整行
只匹配内容完全为“pdsyw”的行。
-A NUM:匹配行及后NUM行
显示匹配“pdsyw”的行及其后的2行内容。
-B NUM:匹配行及前NUM行
显示匹配“pdsyw”的行及其前的2行内容。
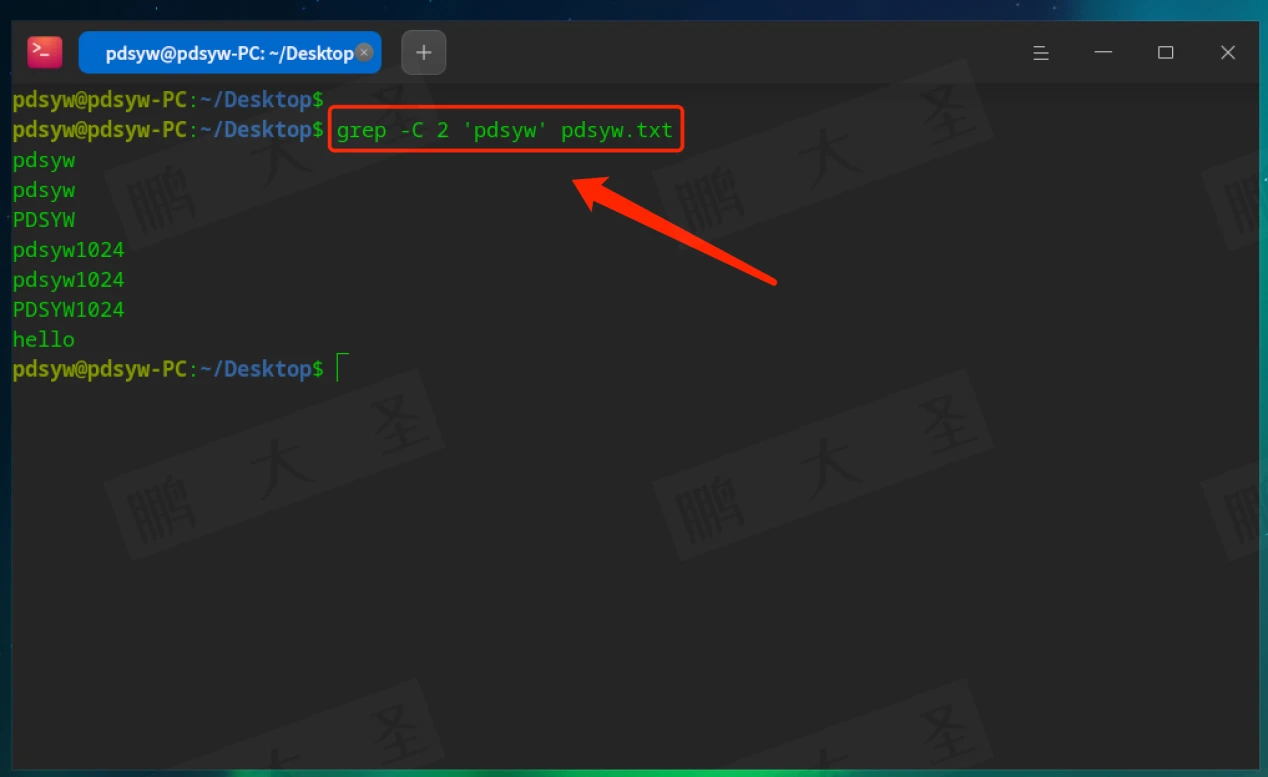
-C NUM:匹配行及前后NUM行
显示匹配“pdsyw”的行以及上下2行的内容。
–color:高亮显示匹配内容
在输出中高亮显示匹配的字符串。
3.正则表达式匹配
grep支持两种正则表达式:基本正则表达式(默认)和扩展正则表达式(-E选项)。
基本正则表达式(BRE)
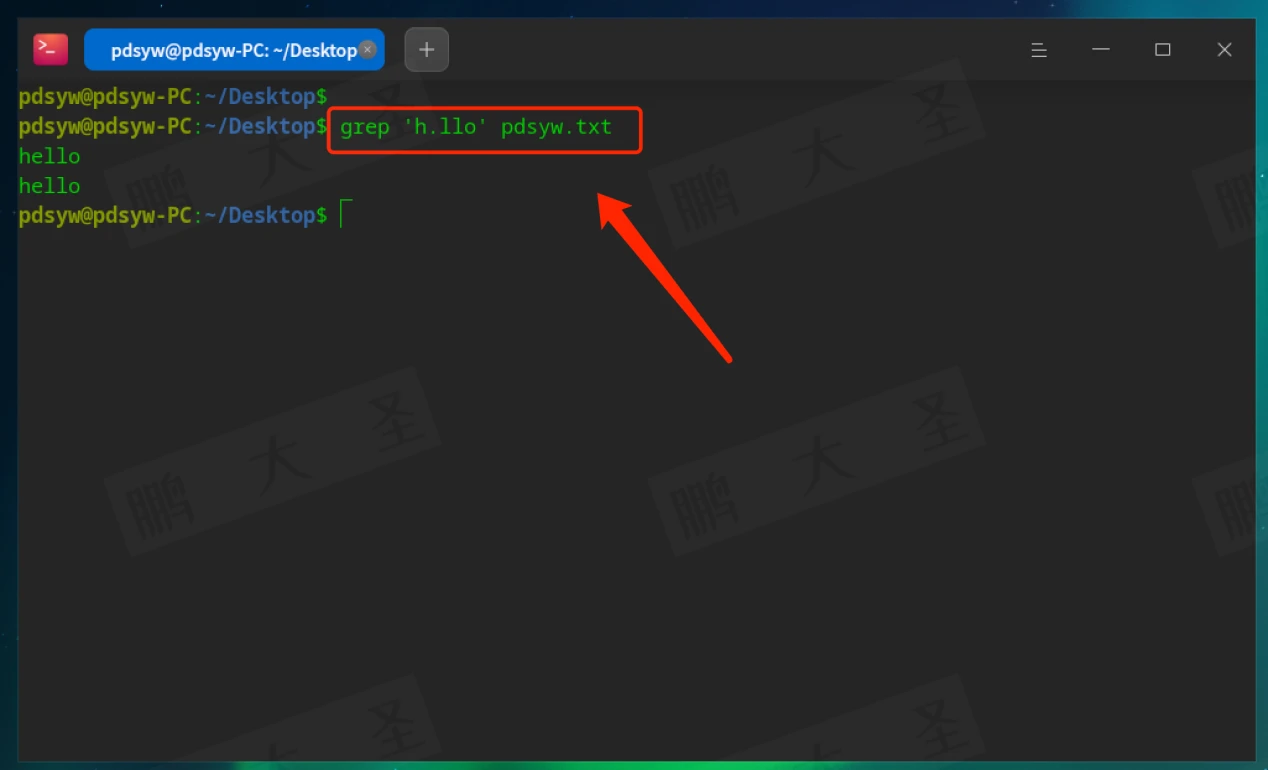
.:匹配任意单个字符
匹配如pdsyw、hallo等。
^:匹配行首
匹配以“pdsyw”开头的行。
$:匹配行尾
匹配以“pdsyw”结尾的行。
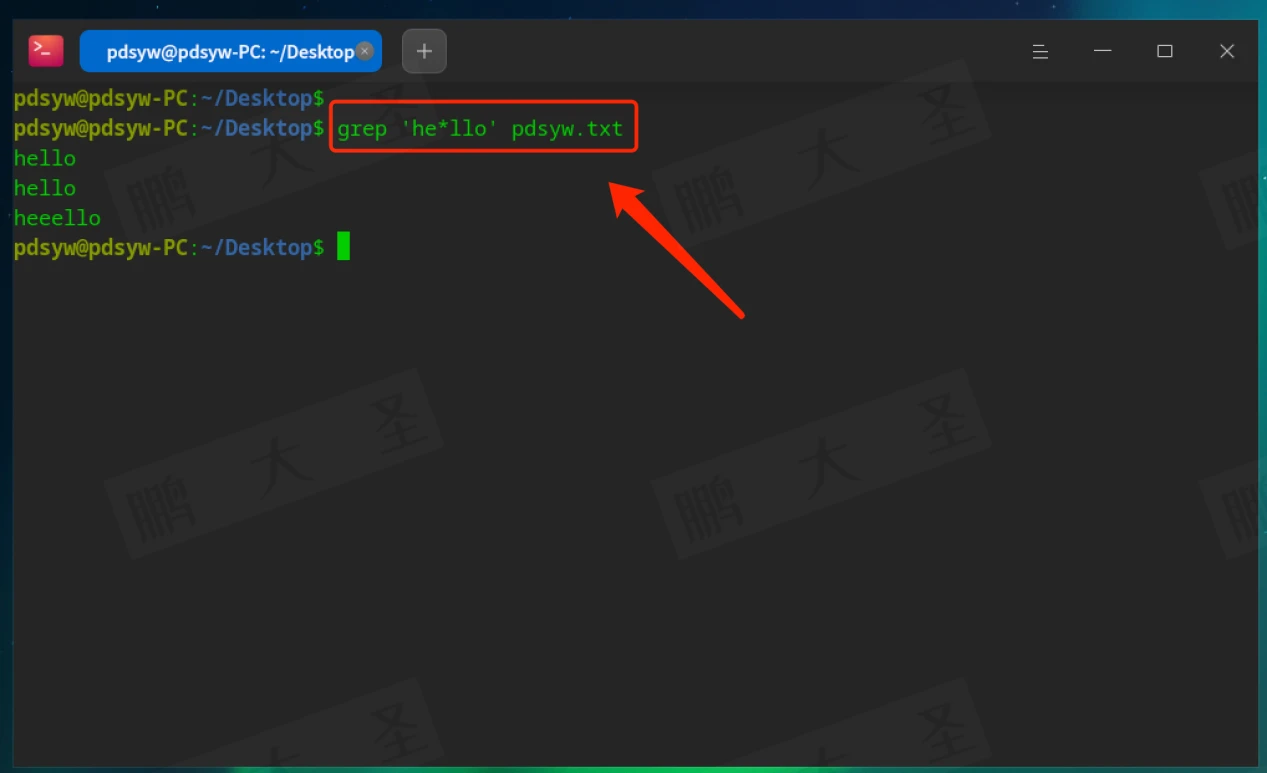
*:匹配前一个字符的零次或多次
匹配如hllo、heeeello等。
4.扩展正则表达式(ERE)
使用-E选项(或使用egrep命令)可以启用扩展正则表达式。
?:匹配前一个字符的零次或一次
匹配如hello和hllo。
+:匹配前一个字符的一次或多次
匹配如hello、heeello等。
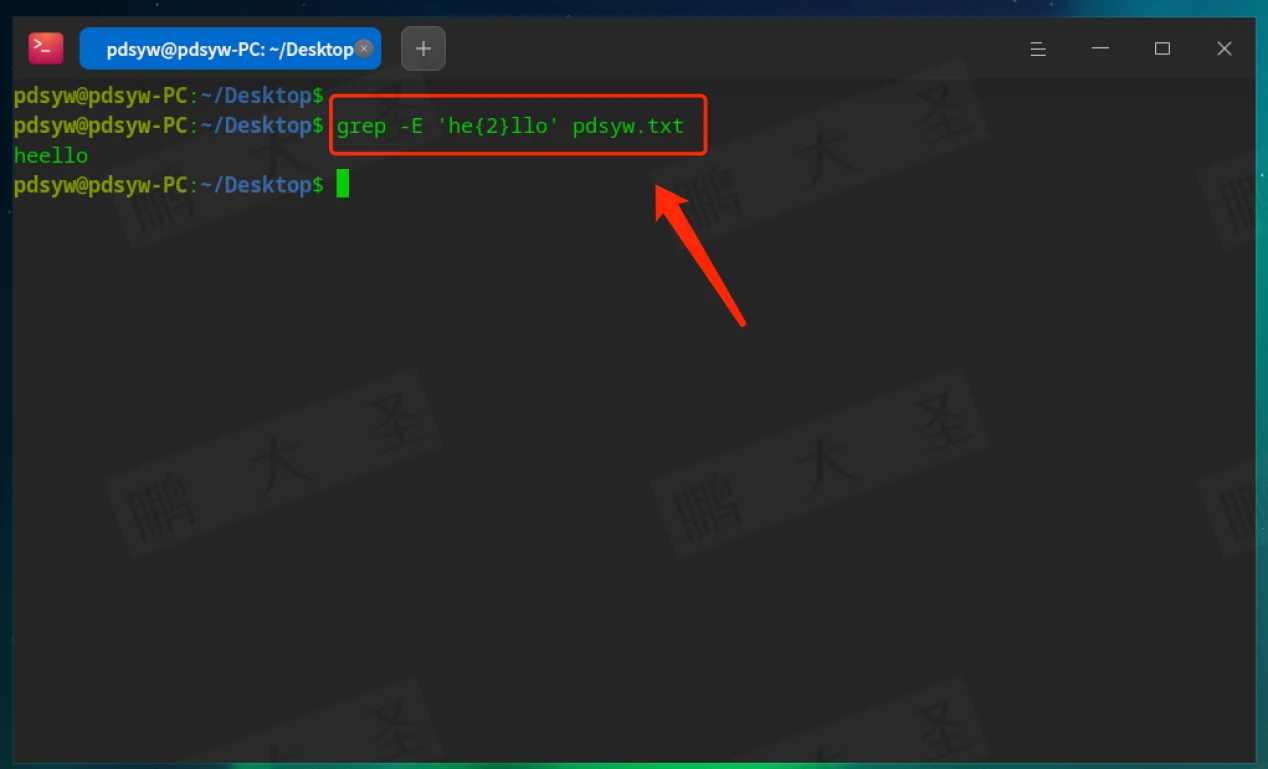
{N}:匹配前一个字符的N次
匹配如heello。
|:逻辑或
匹配“pdsyw”或“hello”。
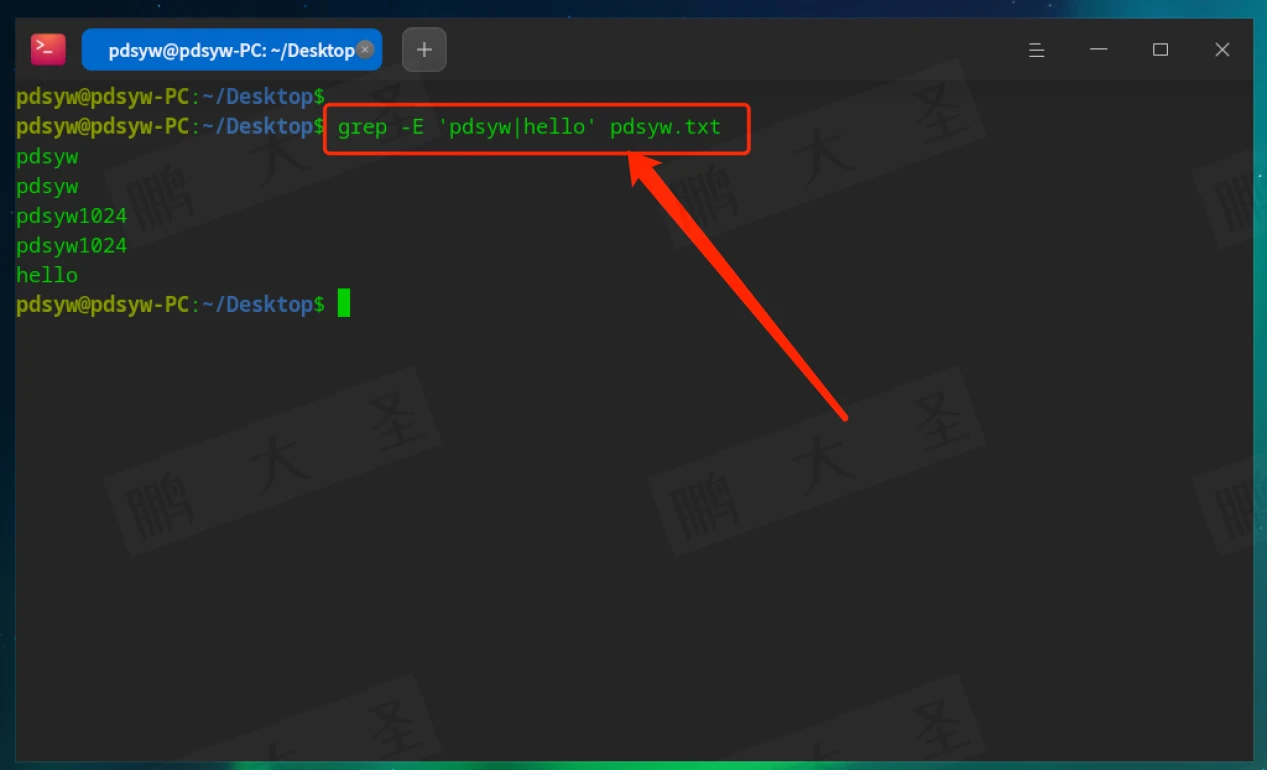
():用于分组
匹配如pdsywpdsyw。
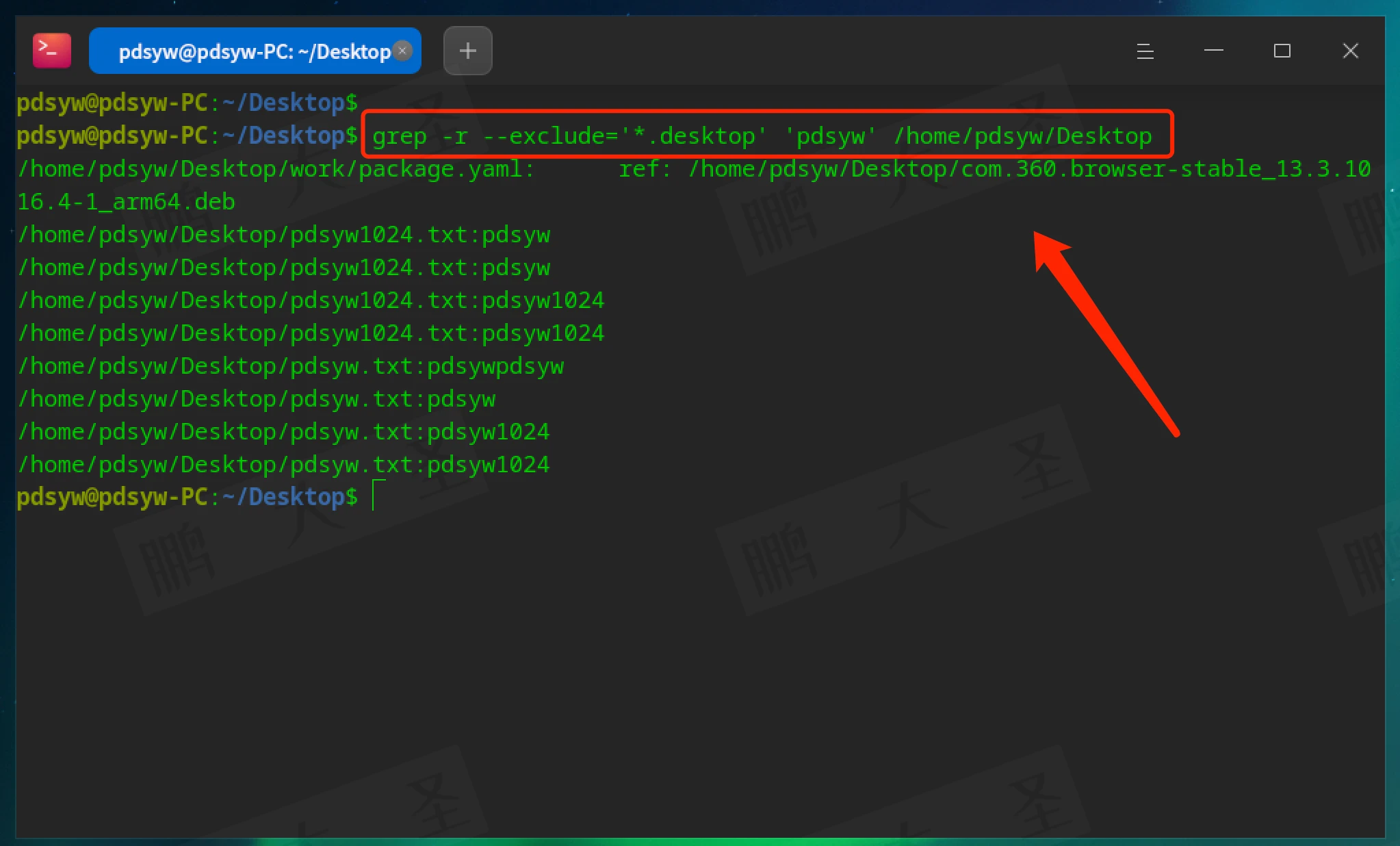
排除特定文件类型(如跳过.desktop文件):
查找并显示指定字符串所在行的前后内容:
5.常见用法示例
查找文件中的所有IP地址:
使用正则表达式提取文件中的IP地址。
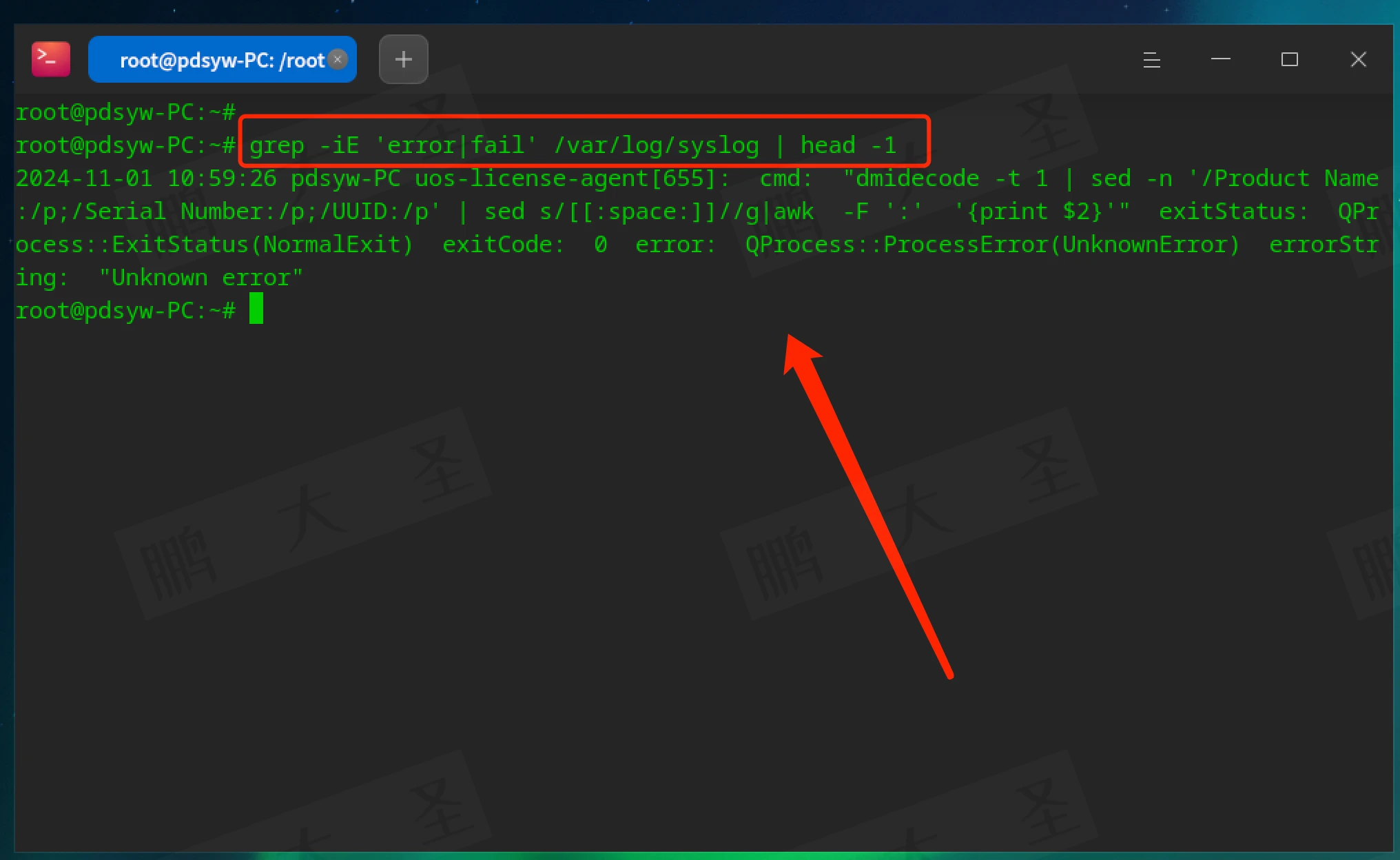
查找含有“error”或“fail”的日志文件:
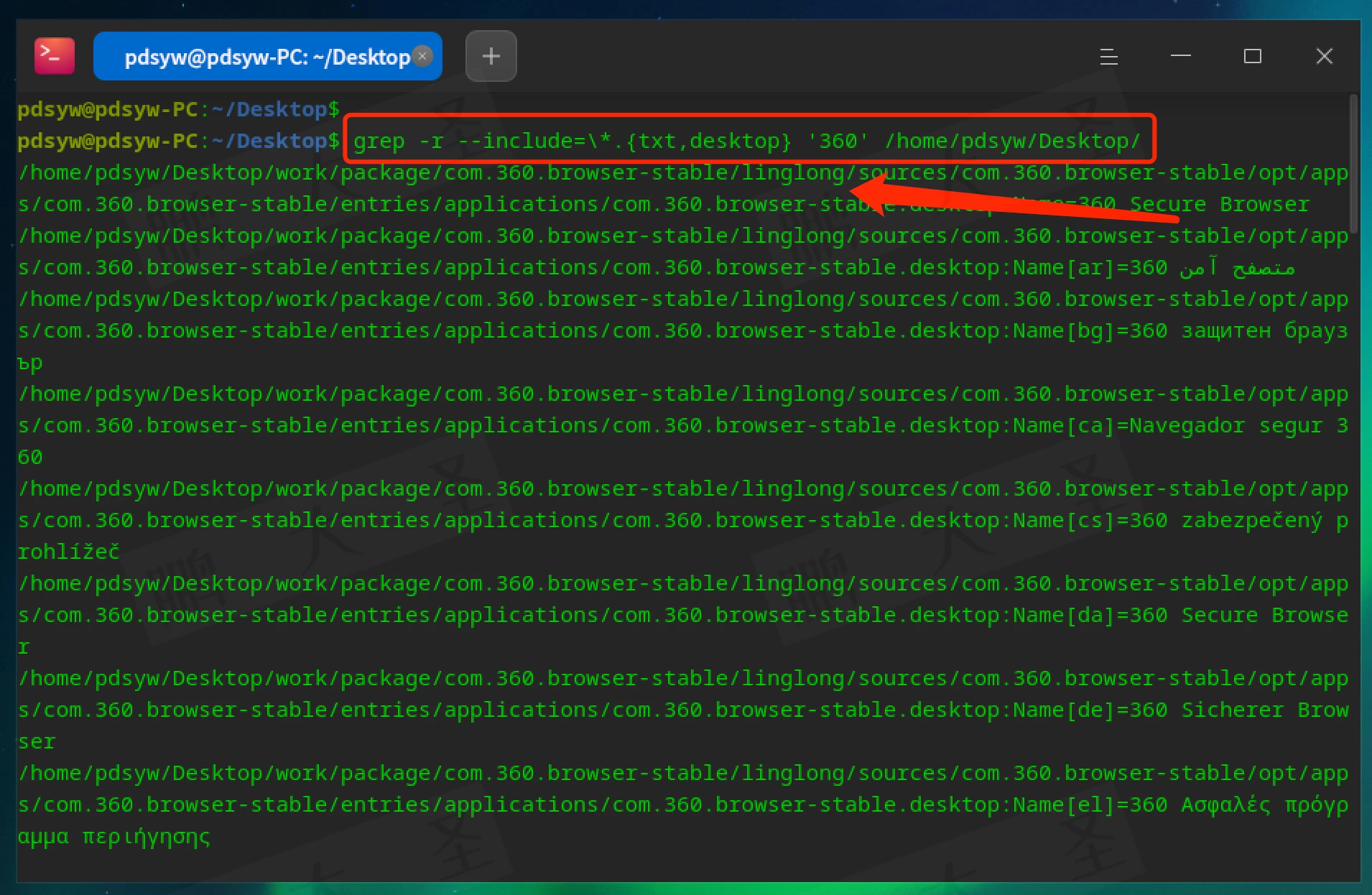
搜索包含特定词的多种文件类型
通过本文的介绍,大家应该掌握了grep命令的基本使用方法和各种应用场景。grep作为Linux系统的三剑客之一,其强大的文本搜索功能为我们提供了高效的文本筛选工具。如果您觉得这篇文章对您有帮助,别忘了分享、转发,并记得点个关注和在看!感谢大家的阅读,我们下次再见!
到此这篇netstat-n命令的作用(netstat命令用法)的文章就介绍到这了,更多相关内容请继续浏览下面的相关 推荐文章,希望大家都能在编程的领域有一番成就!版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/bcyy/21742.html