
“为什么要设计数仓分层?”——这问题应该是做数据仓库搭建的同学在设计分层时首先会形成的疑惑。作为一名数据的规划者,我们肯定希望日后所用的数据能够有秩序地流转,数据的整个生命周期能够清晰明确被设计者和使用者所感知。
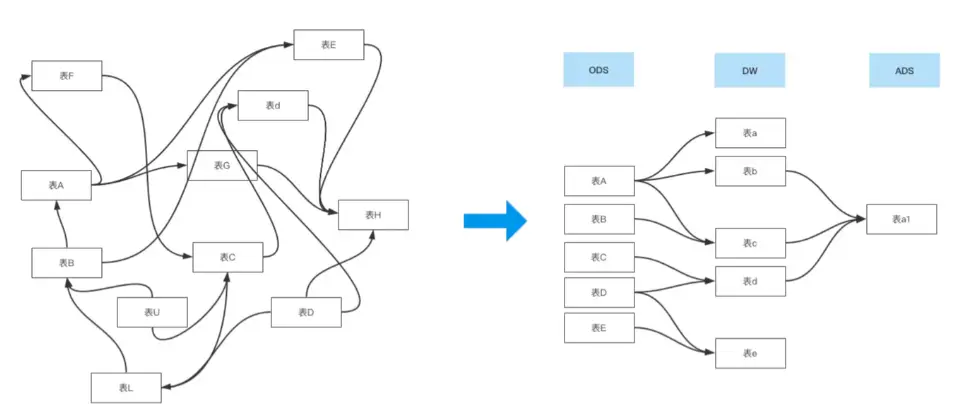
数据分层每个企业根据自己的业务需求可以分成不同的层次,但是最基础的分层思想,理论上数据分为三个层,数据引入层(ODS)、数据仓库层(DW)和数据服务层(ADS)。基于这个基础分层之上添加新的层次,来满足不同的业务需求。
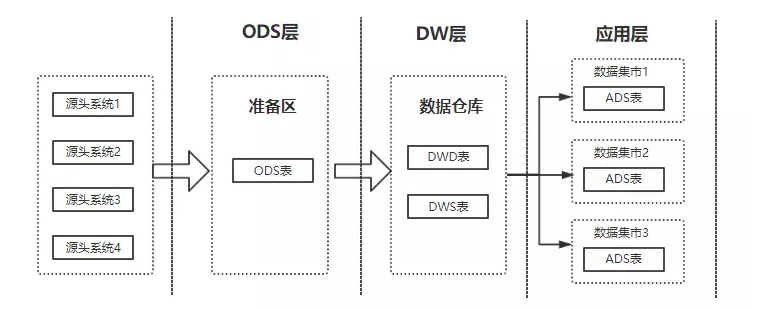
1)ODS层
数据引入层(ODS,Operational Data Store,又称数据基础层),是最接近数据源中数据的一层,这将原始数据几乎无处理地存放在数据仓库系统中,结构上与源系统基本保持一致。这一层的主要职责是解决数据孤岛问题,保证数据集成完整性;数据与源系统表一致,体现非易失性;定期同步,增加表同步时间戳,体现时变性。
ODS层数据的来源方式:
业务库:经常会使用sqoop来抽取,比如我们每天定时抽取一次。在实时方面, 可以考虑用canal监听mysql的binlog,实时接入即可。
埋点日志:线上系统会打入各种日志,这些日志一般以文件的形式保存,我们可以选择用flume定时抽取,也可以用用spark streaming或者Flink来实时接入,当然,kafka也会是一个关键的角色。
消息队列:来自ActiveMQ、Kafka的数据等。
一般来说 ODS 层的数据和源系统的数据是同构的,其内的表通常包括两类,一个用于存储当前需要加载的数据,一个用于存储处理完后的历史数据。历史数据一般保存 3-6 个月后需要清除,以节省空间。但不同的项目要区别对待,如果源系统的数据量不大,可以保留更长的时间,甚至全量保存。
2)DW层
数仓层(DW, data warehouse)是我们在做数据仓库时要核心设计的一层,本层将从 ODS 层中获得的数据按照主题建立各种数据模型,每一个主题对应一个宏观的分析领域,数据仓库层排除对决策无用的数据,提供特定主题的简明视图。在DW层会保存BI系统中所有的历史数据,例如保存10年的数据。
DW存放明细事实数据、维表数据及公共指标汇总数据。其中,明细事实数据、维表数据一般根据ODS层数据加工生成。公共指标汇总数据一般根据维表数据和明细事实数据加工生成。
DW层又可以细分为维度层(DIM)、明细数据层(DWD)和汇总数据层(DWS),采用维度模型方法作为理论基础, 可以定义维度模型主键与事实模型中外键关系,减少数据冗余,也提高明细数据表的易用性。在汇总数据层同样可以关联复用统计粒度中的维度,采取更多的宽表化手段构建公共指标数据层,提升公共指标的复用性,减少重复加工。
3)ADS层
数据应用层(ADS,Application Data Store)存放着数据产品个性化的统计指标数据,报表数据。主要是提供给数据产品和数据分析使用的数据,通常根据业务需求,划分成流量、订单、用户等,生成字段比较多的宽表,用于提供后续的业务查询,OLAP分析,数据分发等。
数仓构建的核心工作是分层及建模,分层架构设计是为应用数据资源采集、存储、处理和交换提供建设性依据,而数据模型将决定数据仓库系统的增长性和性能。
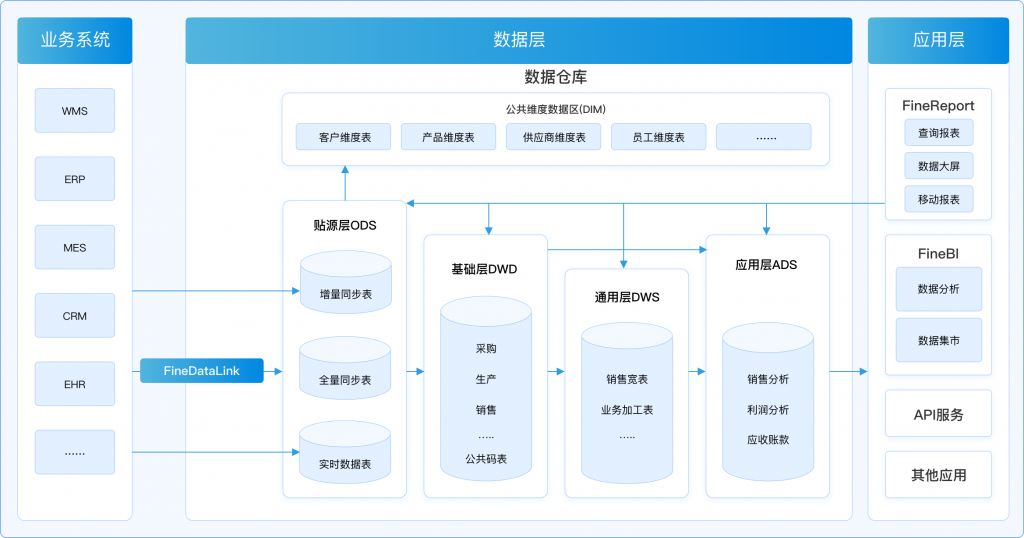
本文的核心在于探讨为什么需要对数据仓库进行分层,并讲解了数据分层的思想和方法。对数仓进行高效分层,便于企业在管理数据的时候,能对数据有一个更加清晰的掌控。
帆软为数仓建设提供生产力工具,若想了解更多数据仓库建设解决方案,请点击:《帆软数据仓库和商业智能解决方案》,另可获取各行业全业务场景数仓搭建案例及资料。
到此这篇如何做分层图(如何做分层图分析)的文章就介绍到这了,更多相关内容请继续浏览下面的相关推荐文章,希望大家都能在编程的领域有一番成就!版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/bcyy/18084.html